17/3/2022

Dziś, przed godziną 4 w nocy, niektóre systemy sterowania ruchem pociągów PKP “doznały awarii“. Problem był ogólnopolski (19 lokalizacji). A potem okazało się że ogólnoświatowy. Wiele pociągów zostało mocno opóźnionych, a część w ogóle nie rozpoczęła swoich biegów. Ze względu na to, co dzieje się obecnie w Ukrainie oraz ze względu na to, że tydzień temu cyberatak spowodował podobne problemy w ruchu kolejowym na Białorusi, część osób zaczęła sugerować, że PKP zhackoWano. Okazuje się że nie…
Zanim jednak przeanalizujemy ten dzisiejszy “medialny Wietnam” i dezinformacyjne narracje, jakie podawały dalej nawet poważne media, uporządkujmy to, co co faktycznie się stało.
Zaczęło się w środku nocy
Jak poinformował nas rano pewien doświadczony “kolejarz”, pierwsze problemy wystąpiły po godzinie 3 w nocy:
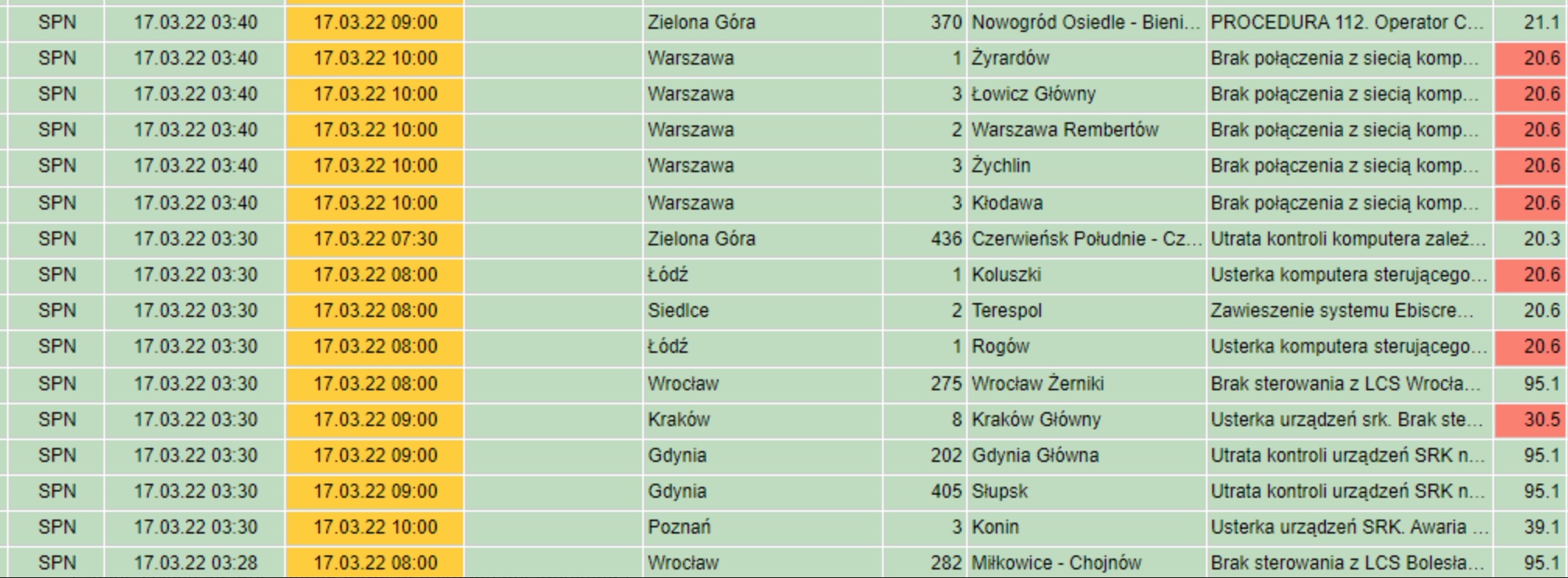
Wszystkie LCSy [czyli lokalne centra sterowania — dop. red.] padły niemal w tym samym momencie, w ciągu 10 minut padło w sumie 19 LCSów i 4 większe stacje sterujące większym obszarem. Większość urządzeń jest produkcji Bombardiera (ZWUS) Polska, jeden – dwa LCSy to urządzenia Thalesa.
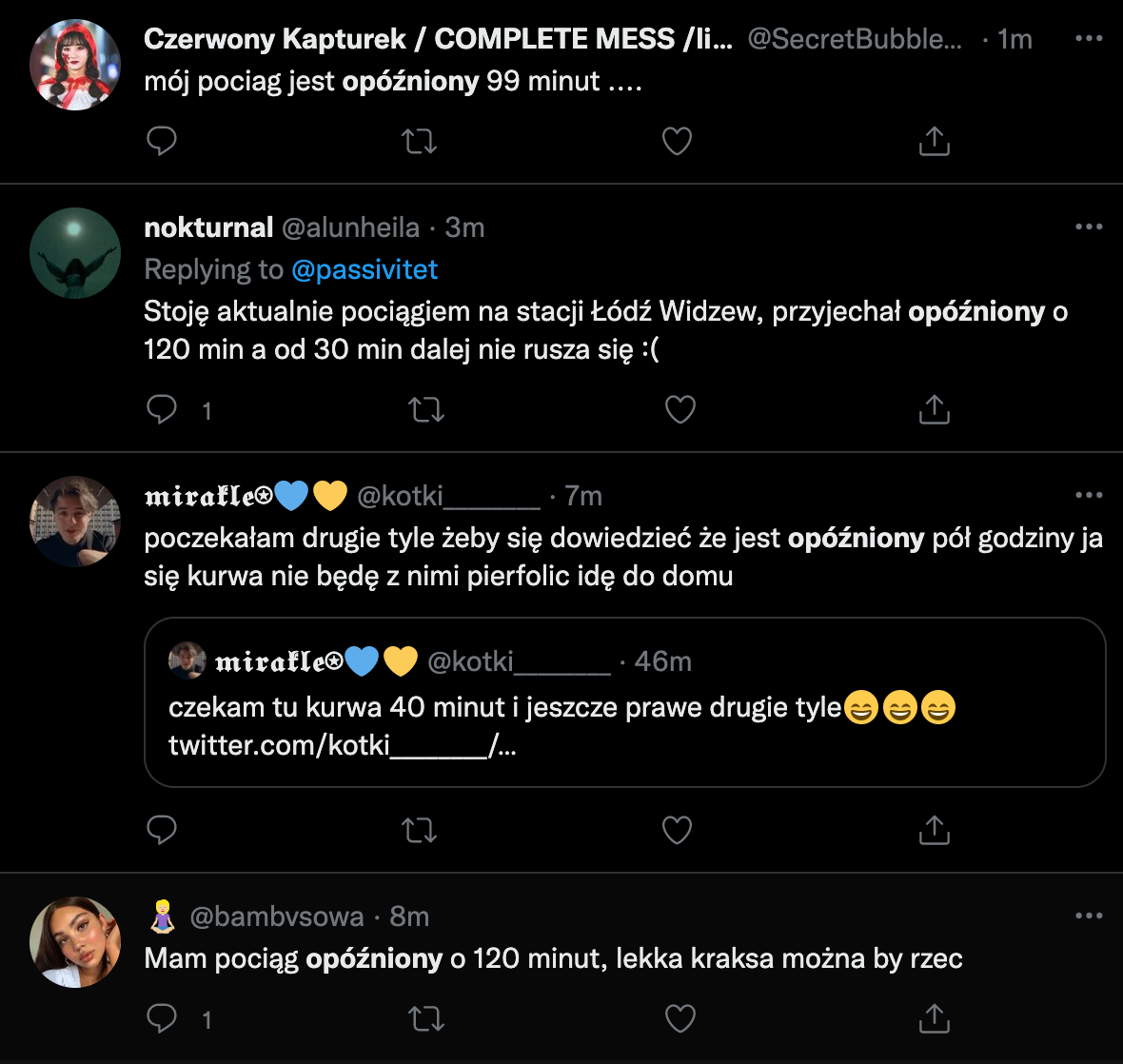
Awaria nie dotknęła wszystkich LCS-ów w Polsce, a tylko (lub aż) 19 — tych, które łączyć miała jedna firma: Alstom. Usterkę tę potwierdzał strumień twitów niezadowolonych pasażerów:
Co było powodem awarii?
Około godziny 12 firma Alstom oficjalnie ujawniła w komunikacie dla Rynku Kolejowego, że ogólnopolską awarię i niemałą panikę wywołał błąd w formatowaniu czasu po stronie ich oprogramowania:
Alstom jest świadomy błędu w formatowaniu czasu, który ma obecnie wpływ na dostępność sieci kolejowej, a co za tym idzie na transport kolejowy w Polsce. Bezpieczeństwo pasażerów nie jest zagrożone. Wdrożyliśmy plan przywrócenia dostępności urządzeń sterowania ruchem kolejowym, aby zminimalizować zakłócenia spowodowane usterką w systemach sterowania ex-Bombardier. Współpracujemy z naszym klientem, aby zminimalizować skutki zaistniałej sytuacji.
Powyższa informacja pochodzi od rzeczniczki prasowej firmy Alstom. My mamy dodatkowo niezależne potwierdzenie od osoby, znającej wewnętrzne szczegóły dzisiejszego incydentu:
Chciałbym uspokoić, że do żadnego ataku nie doszło, aczkolwiek było takie podejrzenie. LCSy są odizolowane od sieci (ta część odpowiedzialna za sterowanie ruchem kolejowym) [usunięto nazwę systemu — dop .red.] jest podpięty do sieci, ale za jego pomocą nie ma możliwości dostania się do SRK [sterowania ruchem kolejowym — dop. red.]. Początkowo były podejrzenia, że ktoś zrobił backdoora w postaci “lewego” łącza, na sieci SRK […] Jednak […] wykluczyłbym taką opcję tym bardziej że na wszystkich LCSach musieli by mieć lewe dojścia, te systemy są wyspowe i nie są ze sobą powiązane sieciowo, wiec musieli by na każdym LCS mieć lewe wejście – raczej mało prawdopodobne. Drugi[m tropem jest] błąd oprogramowania, w którym po określonej dacie przekręca się jakiś licznik i robi się problem. Info z ostatniej chwili […] padł NTP [który jest składową każdego LCS-a] (ta część do nadzorowania nie SRK).
Informacji o tym, że główną przyczyną był serwer NTP nie udało nam się potwierdzić w dodatkowym źródle. Ale zarówno rzeczniczka jak i nasz informator wskazują na ten sam obszar: problem z przetwarzaniem informacji o czasie. Systemy LCS bez poprawnej informacji dotyczącej czasu nie były w stanie funkcjonować. Być może — to wyłącznie nasze spekulacje — podana przez NTP data ze względu na swoją wartość została mylnie zinterpretowana przez oprogramowanie.
W każdym razie, wedle powyższych informacji, przyczyną awarii nie był cyberatak wymierzony w PKP. Co więcej, jak informuje minister Adamczyk, podobne problemy oprogramowanie Alstomu wygenerowało w innych krajach:
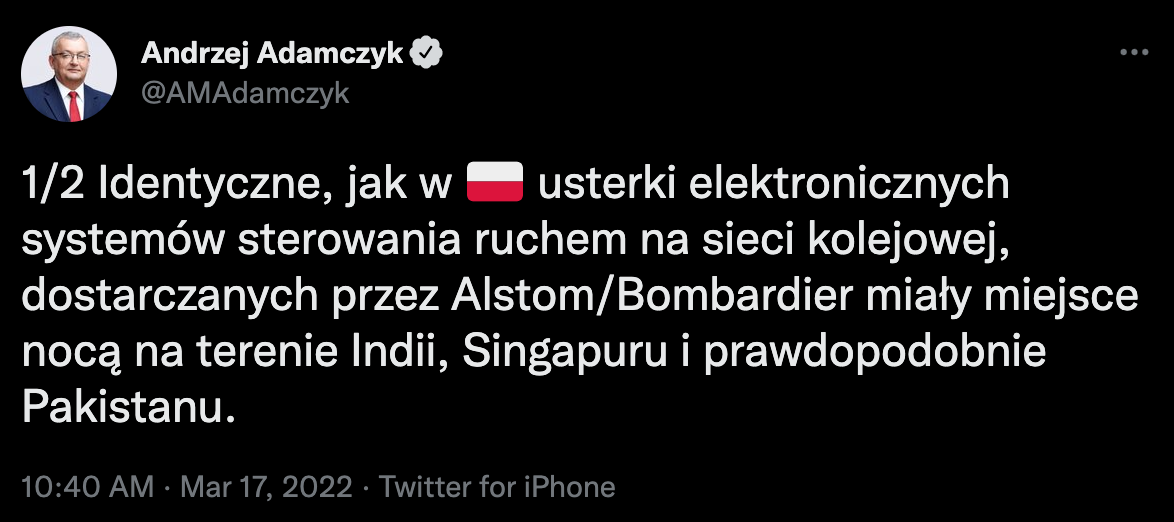
Oczywiście wyjaśnień wymaga jeszcze to, co było przyczyną awarii serwera NTP czy też błędu w formatowaniu daty po stronie Alstomu. Błąd programisty? A może jednak jakieś wrogie działanie? Chociaż malutki sabotażyk? ;-) Z niecierpliwością czekamy na analizę przyczyn tej usterki, ale jak na razie zakres i rozległość ataku nie sugeruje, że było to celowe działanie wymierzone w PKP, bo skutki odczuto także w innych krajach.
Niezależnie od przyczyny, skutek jest taki sam — ogromne zamieszanie w kolejowej komunikacji, która obecnie jest bardzo potrzebna ze względu na transport uchodźców.
I tu ten artykuł powinien się skończyć, ale jest jeszcze jeden aspekt, który warto poruszyć w kontekście tego wydarzenia.
Narracja o cyberataku — analiza dystrybucji nieprecyzyjnych treści
Tak rozległa awaria, wojna w Ukrainie oraz zeszłotygodniowy paraliż kolei białoruskich spowodowany cyberatakiem sprawiły (i to w sumie nawet zrozumiałe), że komentujący pomimo braku posiadania jakiejkolwiek szczegółowej wiedzy na temat incydentu, szybko uznali, że przyczyną dzisiejszego incydentu w PKP musi być atak hackerski. Co więcej, tę narrację podawały dalej nawet profile zawodowo związane z rynkiem kolejowym…
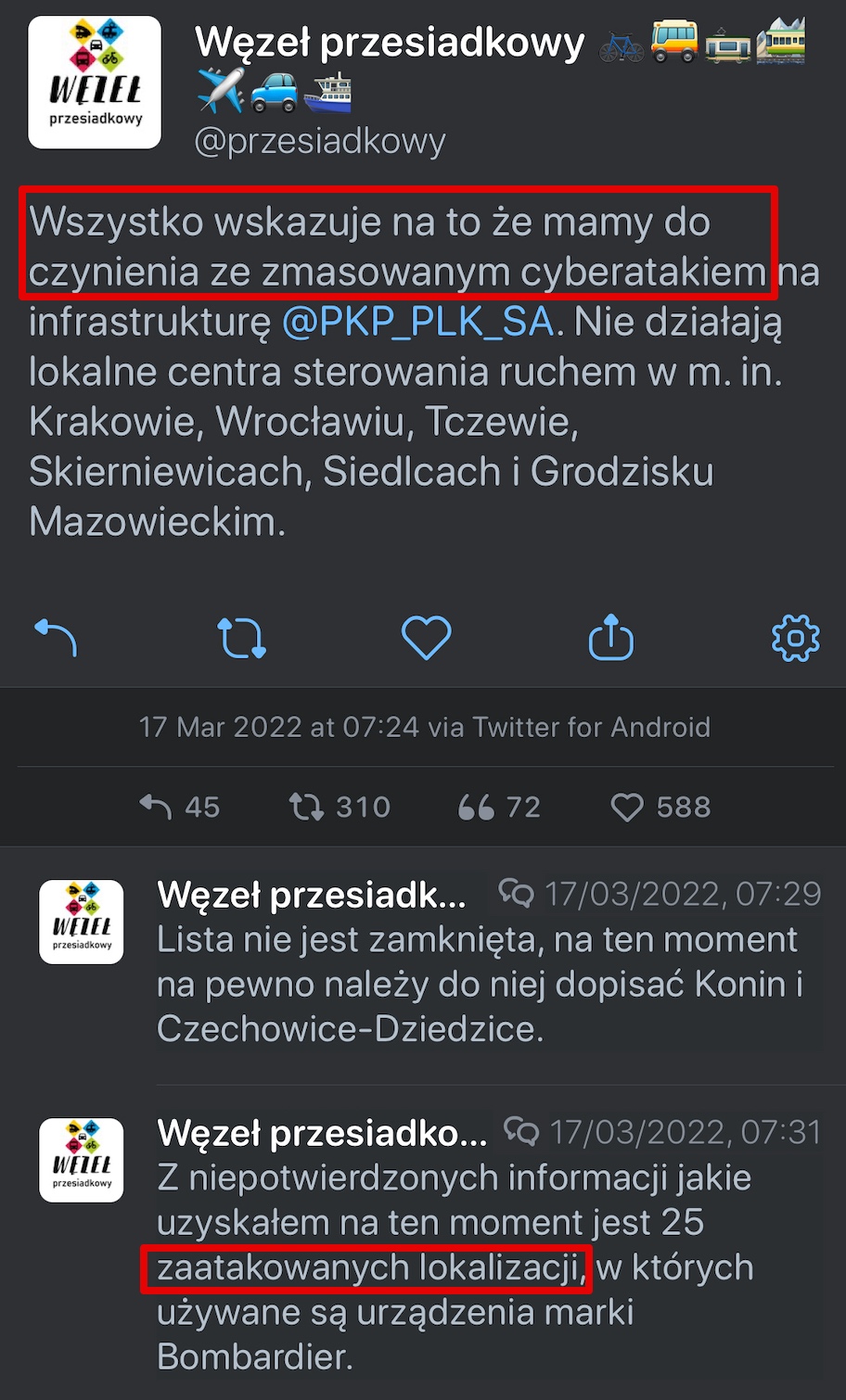
Niektórzy podpierali narrację o “zmasowanym ataku” tym, że nie działał też “Portal Pasażera” z rozkładami jazdy. Ale jego niedostępność była …wynikiem tego, że po prostu pasażerowie opóźnionych pociągów liczniej niż zazwyczaj odwiedzali ten serwis!
Widzieliśmy dziś wiele ciekawych wypowiedzi na temat przyczyn awarii. Zdania o “rzeźbie na produkcji“, o “ataku ransomware“, a nawet o “odtwarzaniu danych z kopii zapasowych“. Oraz wiele, wiele innych, wypowiadanych z pewnością, nawet przez ludzi powiązanych z branżą IT/ITSEC…
“Rosyjski cyberatak na polską kolej?” — pytała w nagłówku jedna z dużych gazet. Ba! Pojawiły się nawet materiały prasowe informujące, że sam prezes PKP SA sugerował, że “mogło dojść do cyberataku“, a informacje o “zaatakowaniu systemu kolejowego w Polsce” podawali na swoich profilach w mediach społecznościowych śledzeni przez setki tysięcy Polaków dziennikarze. Też bez podania źródła tej rewelacji, czy jakichkolwiek dowodów (darujemy sobie zrzuty ekranu, bo rozumiemy, że niektórzy z kolegów po prostu siedli do twitterka przed kawą, jeszcze nie do końca rozbudzeni… Sprawdzimy za to, czy te twity znikną do końca dnia.)
Powiedzieć, że skala tego głuchego telefonu nas zaskoczyła, to nic nie powiedzieć. Wszystko podawane jako pewnik, bez oficjalnego potwierdzenia, bez podania żadnego źródła. Plotka rodziła plotkę. I co najlepsze — nie były to działania dezinformacyjne “inspirowane” przez rosyjskich troli. Polacy sami siebie dezinformowali i nakręcali. Zupełnie, jakby niektórzy chcieli, żeby ten cyberatak na PKP był prawdą…
Zanim napiszesz o kolejnym “cyberataku” na polskie firmy…
Mamy prośbę. Zanim podasz dalej w swoje media społecznościowe wiadomości o kolejnym cyberataku na polskie firmy, o jakim pojawić mogą się informacje jutro, pojutrze lub za miesiąc, to zrób wcześniej te dwie rzeczy, nie bądź siewcą dezinformacji w tych niespokojnych czasach:
- Obejrzyj nasz krótki poradnik jak rozpoznać dezinformacje i jak weryfikować informacje.
- Sprawdź nasz profil na Twitterze — ponieważ zawodowo opisujemy cyberataki, jesteśmy informowani o większości incydentów jako jedni z pierwszych, ale o ataku piszemy tylko wtedy, kiedy mamy jego potwierdzenie. Jeśli nie znajdziesz u nas potwierdzenia takiego ataku, to najprawdopodobniej nie był to “cyberatak”, albo jeszcze nie można z pewnością powiedzieć, że faktycznie był…
⚠️ Kolejarze-Czytelnicy Niebezpiecznika informują, że padły kolejowe LCS (Lokalne Centra Sterowania). Nie działa SRK.
Na razie oficjalnie nikt nie mówi o "cyberataku". Trzeba czekać na więcej info co do przyczyn.
Opóźnienia dziś będą ogromne…
Masz info w tej sprawie, pisz DM
— Niebezpiecznik (@niebezpiecznik) March 17, 2022
Zwróćcie jednak uwagę, że w naszym komunikacie podkreślaliśmy od początku, że jest za mało danych aby mówić o sugerowanym już wtedy przez innych “cyberataku”. I do momentu publikacji tego artykułu, wciąż takich wiarygodnych informacji brak.
Szkolenie/LIVE z dezinformacji
Wygląda na to, że przydało by nam się wszystkim trochę praktycznej wiedzy z zakresu wykrywania dezinformacji/troli i weryfikacji źródeł. Planujemy niebawem taki LIVE / webinar o tym jak krok-po-kroku weryfikować informacje i osoby, które je “podają dalej”. Z realnymi przykładami.
Jeśli jesteś zainteresowany udziałem w takim wydarzeniu, dopisz się na listę poniżej, a powiadomimy Cię o dacie startu niebawem:
Weryfikcja! Albo wszyscy zginiemy!
W przypadku dzisiejszej awarii, nie mniej straszne od tego, czy awaria była czy nie była wynikiem “cybarataku” jest to że informacje na jej temat podawano bez wskazywania źródeł i dowodów. Pamiętajmy o tych kwestiach, zarówno kiedy będziemy pisali, że gdzieś był (lub że gdzieś nie było ataku). To ważne, żeby wiadomości przekazywać w sposób wiarygodny.
Nawet, gdyby finalnie okazało się dziś, że ta awaria jest wynikiem ataku, to takie prezentowanie informacji z jakim mieliśmy od rana do czynienia, wciąż jest problemem. I może się na nas wszystkich w przyszłości zemścić.
Jeśli w sprawie tego incydentu pojawią się nowe wątki, poinformujemy Was o tym w aktualizacji.
Aktualizacja 17.03.2022, 17:00
Kolejne osoby zaznajomione z dzisiejszym incydentem potwierdziły nam, że przyczyną kłopotów były problemy z interpretacją aktualnego czasu między różnymi elementami systemu zarządzającego ruchem pociągów. Usterkę usunięto poprzez ponowną synchronizację czasów na serwerach.
Aktualizacja 18.03.2022, 11:00
Niezależne od siebie źródła potwierdziły nam, że każdy z LCS-ów ma swój serwer czasu. Podkreślamy to, bo wypowiedź informatora zacytowana w artykule nie była wystarczająco precyzyjna i wprowadziła niektórych komentujących w błędne przeświadczenie, że serwer czasu to SPOF. Uściśliliśmy tę wypowiedź. Dodatkowo, warto wspomnieć, że serwery czasu mogą pobierać dane na temat czasu z różnych źródeł, nie tylko z GPS-a.
Wczorajsza awaria spowodowała anomalie w pracy tzw. komputerów zależnościowych znajdujących się na poszczególnych stacjach kolejowych (to komputery, którymi zarządza dany LCS, ale można nimi sterować również ręcznie, w trybie offline). Inne elementy infrastruktury na stacji, poza komputerami zależnościowymi, działały w trakcie awarii poprawnie. Komputery zależnościowe miały problem właśnie ze względu na problemy z synchronizacją czasu. Co może być istotne, niektóre ze stacji (z LCS-ów które dotknął problem) działały bez przeszkód, a to ma je łączyć, to starsza wersja oprogramowania.
I jak dodaje inna osoba, obsługująca wczorajszy incydent:
Kolej jest miejscem gdzie na prawie wszystko jest procedura. I nie było inaczej w tym przypadku. Natychmiast po zaobserwowaniu awarii dyżurni automatycy udali się na obiekty. Po stwierdzeniu braku szybkiego rozwiązania problemu przystąpiono do procedur podanych w instrukcjach PKP PLK. Wszystkie rozjazdy ustawiono na wprost oraz zamknięto fizycznie kluczami. Ruch na tych stacjach był znacząco utrudniony. Dyżurni nie mieli możliwości wyprawiania pociągów za pomocą semaforów, więc musieli to robić za pomocą rozkazów pisemnych. Dyżurny wypełnia odpowiedni dokument, następnie dyktuje go maszyniście. Ten musi to zapisać i odczytać. Dopiero po takiej procedurze można pominąć semafor wskazujący STÓJ, czyli stan zasadniczy (w tym przy braku kontroli). Czas który jest potrzebny na wydawanie rozkazów pisemnych, oraz to, że wielu miejscach było przez ten fakt ograniczenie prędkości do 20 km/h. Były miejsca gdzie nie było kontroli na np. tylko dwóch stacjach podlegających pod LCS. Taka sytuacja nie była tragiczna, robił się tylko korek w wąskim gardle. Niestety były też take LCSu, które padły całe. To jest dopiero problem organizacyjny.
Analiza tego incydentu trwa. Na razie, wedle naszych informacji, wciąż nic nie wskazuje, że powodem usterki był atak z zewnątrz. Mimo to, wedle naszego informatora, dzisiejszy incydent ujawnił pewną słabość. Systemy, które projektowano by działały nawet przy problemach w komunikacji ze sobą, nie do końca potrafiły odnaleźć się w takiej sytuacji i pracować niezależnie. Oby wnioski zostały wyciągnięte, a poprawki szybko wprowadzone.
Aktualizacja 18.03.2022, 12:05
Kolejne, niezależne osoby, które się z nami kontaktują, wskazują na poniższy problem jako źródło wczorajszej awarii:
Awaria była spowodowana “przekręceniem” się kalendarza w komputerach sterujących ruchem kolejowym [nazwa konkretnego oprogramowania usunięta]. Na skutek tego komputery [zależnościowe — dop. red.] zaczęły się restartować, co uniemożliwiło sterowanie ruchem z systemu nadrzędnego [nazwa innego oprogramowania usunięta]. Przyczyna leżała w oprogramowaniu komputera (hardware), nie w samym oprogramowaniu sterującym ruchem.
PS. Jeśli macie dodatkowe informacje do dzisiejszego incydentu, zapraszamy do kontaktu. Nasz formularz działa z sieci TOR, a my gwarantujemy anonimowość.


 Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów!
Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów! Każdy powinien zobaczyć te webinary! Praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy oraz darmowy webinar.
Każdy powinien zobaczyć te webinary! Praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy oraz darmowy webinar.
NTP systemów krytycznych poza kontrolą użytkownika tych systemów?
Skoro same systemy są “poza kontrolą” w sensie obsługi awarii, to czemu się dziwić, że serwer NTP jest również “poza kontrolą”. Jedyne czemu można się dziwić, to dlaczego nie zostało zestawionych więcej serwerów NTP (niektóre poradniki podają, że dla redundancji zalecane jest minimum 4).
Ja to w ogóle tego nie rozumiem co informator niebezpiecznika twierdzi. To znaczy, że systemy są nie połączone z siecią, a potem nagle się pojawia NTP. NTP to jest po sieci… Jak pobierają coś z sieci, to szansa na dostanie się do tej sieci jak najbardziej istnieje.
Zresztą to wygląda jakby z sieci właśnie pobrali update, który rozwalił system. Istnieją oczywiście różne problemy z formatowaniem czasu, ale same się te problemy nie zrobią i na pewno nie jednocześnie w różnych miejscach w Polsce. Normalnie bym pomyślał, że ktoś może zmienił locale w systemie, ale przecież nie zrobił tego w “odizolowanych” od sieci i od siebie systemach (podobno systemy są wyspowe).
Coś te systemy jednak łączy i nie wygląda jakby je łączył tylko NTP.
Rzeczywiście dość nieskładnie ten informator się wyraził, jednakowoż rysowany przez niego obraz architektury jest wiarygodny. Ja rozumiem go tak, że LCSy są od siebie niezależne i niepodpięte do internetu w warstwie sterowania ruchem ale w warstwie monitoringu są ze sobą połączone i wymieniają dane. Serwer NTP może być jeden, centralny lub może być ich wiele, po jednym w każdym LCS`ie.
Obawiam się, że określenie “padł NTP” nie oznaczało awari serwera NTP a awarii komunikacji lub interpretacji danych dotyczących czasu między serwerami w LCS.
Ale skoro awaria rozwiązań Alstom była globalna. Skoro wystąpiła jednocześnie w całkowicie odseparowanych od siebie lokalizacjach i organizacjach w różnych krajach. To w oprogramowaniu interpretującym czas lub w funkcji synchronizacji czasu był jakiś bug. I ujawnił się po konkretnej liczbie sekund od EPOCH, która wybiła dziś po godzinie 3AM CET.
Nie bylo zadnego ataku, po prostu nasz nowy programista Dmitrij sie pomylil xD
Czyli “problem roku 2022” jednak istnieje
Tak sobie czytam:
1. “LCSy są odizolowane od sieci ”
2. “te systemy są wyspowe i nie są ze sobą powiązane sieciowo”
3. “padł NTP z którego korzystały LCSy”
Acha …
I trzy pytania od nooba:
1. Jak się ma problem z formatowaniem czasu do padnięcia NTP?
2. Skoro połowa systemów pada niemal w tym samym czasie, to potencjalny błąd jest powiązany z jakąs konkretną wartością czasu. Ale jeśli tak, to dlaczego druga połowa też nie padła?
3. czy moglibyście się dopytać na czym polega ten rzekomy problem z formatowaniem czasu?
to samo sobie pomyślałem – co ma padnięcie komunikacji z prawidłowym rozwiązywaniem czasu to pojęcia nie mam … i dlaczego to samo urządzenie nie padło w Zielonej górze i kilku innych miejscach – te wyjaśnienie się kupy nie trzymają
Artykul sugeruje ze wypowiedz informatora moze nie byc uproszczeniem. Jesli zalozymy, ze dazne z servera NTP software alstomu pchal w jakas zmienna i potem z nia cos robil, to spokojnie kazda z niezaleznych wysp jak pracowala na tym samym software mogla tak samo zcraszowac po odczycie tej samej wartosci czasu. Przeciez nawet jak sa rozne NTP w kazdym z LCS to musza podawac te same wartosci czasu.
Ale bez fragmentu kodu zrodlowego tego softu to mozemy sobie dywagowac co oni tam zakodzili i jak to parsowali.
Jako programista widzę to tak:
jeśli rzeczywiście przyczyną było że padł serwer NTP to znaczy że aplikacja nie była w stanie pobrać aktualnej godziny a tym samym jej sformatować, czyli coś w tym stylu (pseudokod):
time = getTime(); //miał być jakiś obiekt, a przyszedł null / false / wyjątek
time.format();// albo sie nie wykonało albo wybuchło próbując formatować coś czego nie ma
@Damian w wypadku niedostępności NTP system powinien mieć lokalnie dalej w miarę aktualny czas.
Serwery czasu są odpytywane co jakiś czas przez OS (np. via nptd) i lokalny zegar systemowy jest synchronizowany z czasem podanym poprzez NTP.
Syscall o podanie czasu typu time() nie powoduje wysłania żadnego zdalnego zapytania o czas tylko zwraca lokalny czas systemowy, nie wiem co by się musiało stać żeby tam był null. Patrząc na korelację czasową 100% błąd w oprogramowaniu a nie problem NTP
A, no chyba że w samym kodzie była zaimplementowana obsługa NTP i dzwonienie zdalnie o czas, zamiast poleganiu na lokalnym czasie i periodycznej aktualizacji, no to pozdro. Raz że to masywny narzut czasowy, dwa – SPOF
Do JohanX i inni. Zapomnieliście o kluczowym cytacie z wypowiedzi informatora. “[usunięto nazwę systemu — dop .red.] jest podpięty do sieci, “. Część infrastruktury tzw LCS jest zcentralizowana.
Czyli systemy infrastruktury krytycznej z “designem” wyspowym padły jeden po drugim, bo mają spof’a w postaci NTP? Sam już nie wiem co lepsze .. :)
Wspólny NTP systemów “wyspowych” – o zgrozo :D
Z tresci nie wynika ze to byl ten sam serwer. Ich moglo byc kilka. I co chyba spodziewane każdy musiał podawać ten sam czas :]
Hm… NTP sie sam z siebie rozsypał? Aż by się chciało przejrzeć listę otwartych bugów.
Jednak jakkolwiek ‘sam z siebie NTP sie rozsypał’ (jak do dobrze brzmi!) to jak rozumiem za straty filma Alstom staje sie firma upadłą. I co my teraz z taką padliną zrobić? Bo zeby firma robiąca oprogramowanie do infrastruktury krytycznej zrobiła AZ TAKIEGO babola ze nie sprawdza poprawnosci danych przychodzących od softu third pary umieszczonego w sieci (nawet prywatnej) nie uwierze. Prędzej w to ze ktoś zrobił takiego ‘buga’ do wyłączenia sieci kolejowej ‘w razie czegoś….
Przy okazji – lista krajów dotkniętych ‘awaria’ zdaje się jest niekompletna.
Co do fake newsów – weryfikujmy i myślmy proszę.
To, że NTP się rozsypał to nic – takie rzeczy się zdarzają i system powinien być na to odporny… Dla mnie niepojęte jest to, że tak krytyczny system opiera się jak widać na jednym (sic!) serwerze NTP, nie ma jak widać, żadnego failovera na taką ewentualność oraz nie weryfikuje formatu czasu, jaki się mu podaje… I znów – gdyby to był jakiś studencki projekt – to można by przymknąć oko… ale to jest system sterowania ruchem kolejowym – rzecz krytyczna z punktu widzenia bezpieczeństwa ruchu na kolei i bezpieczeństwa krajowego…
@Matt_
Wiekszosc ludzi nie zdaje sobie sprawe jak wielka czesc kosztow produkcji systemow tego typu stanowi niezawodnosc – ktorej tutaj ewidentnie nie dostarczono…
To ja na szybko wytłumaczę dlaczego awaria nie objęła całej sieci. To dlatego, że urządzenia są produkowane przez różnych producentów. Co ciekawe to urządzenia Bombardiera dotychczas uchodziły za najlepsze urządzenia na rynku…
daty się nie przetwarza datę się pobiera i tyle
Przyczyną awarii był serwer NTP czy też błąd w formatowaniu daty po stronie Alstomu … tiiaaaa … lepiej podać kilka przyczyn niż jedną bo i tak nie wiemy co się stało :)
kiedys tak bywalo, ze brak synchronizacji czasu (atak na serwer ntp) prowadzil do roznych problemow z weryfikacja certyfikatow ssl.
I też ogromnie ilości innych potencjalnych problemów, w systemach które polegają na dobrym zsynchronizowanym czasie takie rzeczy się zwyczajnie monitoruje. Swojego czasu jak pracowałem w sektorze finansowym to mieliśmy checki na Zabbixie które przy rozjeździe lokalnego czasu systemowego o więcej niż 30 sekund od razu nam wyskakiwał alert żeby to ogarnąć.
Zarządcą infrastruktury jest PLK, a nie PKP.
Aż strach pomyśleć co się będzie działo 19 stycznia 2038 o 3 w nocy :-)
nic 32-bitowego sie nie biedzie dzialo w tych czasach.
Oj mało widziałeś. Niecały rok temu widziałem urządzenia sprzed ponad 20 lat pięknie komunikujące się po IP. Nie sądzę, by ich bezpieczeństwo było na poziomie tych obecnych, a co najwyżej security-by-obscurity.
Tyle sie teraz wstawia Raspberry Pi (na próbe, tymczasowo, “tylko zeby byly logi”) nie tam gdzie trzeba, że na bank zostanie gdzieś coś na raspbian 32bit. Kilka lat temu wymieniałem moduł ethernet w PLC (chyba siemens) i jak otworzyłem obudowę to zobaczyłem procek 386.
Jednym słowem – PKP.
W tytule stwierdzamy, że cyberataku nie było, a z drugiej strony nie mamy potwierdzonej przyczyny awarii. Artykuł wpisuje się w burzę medialną i brakuje w nim faktów. Jeśli podejrzewamy, że padł serwer ntp to dlaczego nie padły wszystkie LCS? Tylko cześć była do niego podłączona, a reszta do innego?
Nie chcę dolewać oliwy do ognia i siać dezinformacji, ale wczoraj po południu pracownicy jednej z wrocławskich firm zostali ewakuowani ze względu na “incydent chemiczny” – ta firma to… Alstom :) Dobry przypadek, prawda?
A moja ciocia wczoraj słyszała, że kosmici wylądowali na spotku w katowicach! Nie obraź się, ale pisanie takich komentarzy jak Twój bez podawania choć linka do informacji w lokalnych mediach powinno kończyć się banem. A nawet jak podasz linka, to przecież we Wrocławiu jest zakład przemysłowy Alstom. A w zakładach takie ewakuacje się zdarzają. Ludzie wszędzie zobaczą spisek, jeśli go szukają.
@Seba
Szukanie dziury w całym. Jak w 2015 odchodziłem z pracy z zakładu Alstomu we Wrocławiu, to produkowaliśmy generatory do elektrowni a nie urządzenia SRK*, co więcej właśnie wtedy właścicielem fabryki został General Electric. Więc.
SRK = Sterowanie ruchem kolejowym
@uxE
Proszę, oto przykładowy link do wspomnianej przez @Seba sprawy: https://wroclaw.naszemiasto.pl/ewakuacja-zakladu-przy-ul-fabrycznej-we-wroclawiu-na/ar/c1-8726133
Każdemu tak z góry podważasz przyniesione informacje?
https://www.tuwroclaw.com/wiadomosci,akcja-strazakow-i-ewakuacja-kilkuset-osob-we-wroclawiu-co-sie-stalo,wia5-3266-64293.html
Strumień danych wejściowych przekierował potok instrukcji procesora na nieprzetestowaną ścieżkę wykonawczą :-P
Czesc LCS jest podpieta do internetu. Nie chciałbym tu ujawnić zbyt dużo, ale przy tym jak pospinano te system jest możliwe że awaria w NTP na sieci monitorigu położyła całość.
Czyli nieudany atak za pośrednictwem słabo zabezpieczonych serwerów NTP?
Serwery NTP nie muszą być osiągalne z publicznego internetu. Nie muszą nawet wcale być do niego podpięte.
Oczywiście, ale autonomiczne serwery NTP kosztują. Każdy jeden. :-)
Co gorsza trzeba je jeszcze układać co najmniej parami!
Jak “niezależne” serwery NTP korzystały, tak jak kryptografia NATO, z czasu od GPS, to jego zakłócenie (przez Rosjan lub przez… NATO by rosyjskie Kalibry z GPS nie korzystały) mogło je wyłożyć. Tak Rosja w Syrii paraliżowała amerykańską łączność i radary – zagłuszając sygnał czasu z GPS…
Wniosek: jesteśmy Indiami i Pakistanem kolejnictwa…
Mozę mieli ustawione że Luty ma 31 dni – tak na przykład miał Blizzard w grze SWGOH i się zapetłay questy
Może to coś w stlu GPSD Rollover Bug.
Nawet jeśli jakieś urządzenie korzysta z systemu GPS do synchronizacji czasu, to jest bardzo mało prawdopodobne aby zagłuszanie tego systemu spowodowało błąd synchronizacji. Informacja o czasie jest bowiem najbardziej podstawową daną w systemie GPS, którą odbiornik udostępnia jako pierwszą na swoim wyjściu, bo wystarczy mu do tego łączność z jednym satelitą.
Skoro system poza siecią, to czemu nie czas z GPS albo z DCF777? Pewnie to coś innego było niż problem z NTP.
A swoją drogą, PKP mnie wkurza. Latami “walczyli” by klienci uciekali w samochody i BUS-y, a teraz pchają kupę kasy w pociągi, które najczęściej wożą powietrze. W mojej okolicy, remontując tory, zniszczyli 20km drogi, rozjeżdżając ją wywrotkami z kruszywem. W dodatku, po tym remoncie, dłużej stoję na przejeździe, bo wspaniała automatyka każe dróżnikowi zamknąć szlabany chyba jak pociąg jest jeszcze na poprzedniej stacji…
Moim skromnym zdaniem, a w tworzeniu wielu systemów brałem czynny udział, pierwotna i ściśle ukrywana przyczyną takich awarii jest też tworzenie oprogramowania przez księgowych. W skrócie chodzi o to że dziś w przytłaczające większości takich projektów największy nacisk kładzie się na jak najniższe koszty potem na jak najszybszy czas realizacji a o jakość powstałego systemu i oprogramowania to martwi się co najwyżej dział marketingu i to tylko pod względem tego żeby klienci myśleli że ktoś się takimi kwestiami zajmuje. Przykre to ale jeśli rzeczywiście przyczyną był błędny znacznik czasu to znaczy że znowu zaoszczędzono na sanityzacji wejsc
Nie rozumiem na podstawie czego autor artykułu wyklucza cyberatak. Jeśli atak na jeden NTP wyłączył 19 klientów, to IMO nawet bardzo udany atak.
Czy informacja o analogicznych problemach w innych krajach jest gdziekolwiek potwierdzona poza Twitterem pana ministra? Skala chyba dużo mniejsza, bo ciężko coś znaleźć np. o Indiach (najłatwiej szukać po angielsku).
Każdy LCS ma swój NTP.
https://www.arabnews.com/node/2044511/world
https://www.dawn.com/news/1680561/computer-glitch-disrupts-rail-services-in-europe-asia
Ja obstawiałem że to taki happening związany z organizowanym w tym dniu przez Urząd Transportu Kolejowego FORUM BEZPIECZEŃSTWA KOLEJOWEGO 2022 .
Tam o bezpieczeństwie na kolei przez cały dzień była mowa.
https://www.tor-konferencje.pl/wydarzenia/konferencje/forum-bezpieczenstwa-kolejowego-2022-1005.html
Poszczególne LCS-y są odseparowane od siebie .Działają niezależnie od innych LCS-ów. Np. Opolski LCS nie ma nic wspólnego z Wrocławskim Móchoborem . Wewnętrzne Systemy Ebilock ,Ebiscreen działają też bez tego całego serwera NTP. Pobierają tylko wzorcowy czas i nic więcej.
To trochę grubsza afera ale tak jest wygodniej powiedzieć że to nie wina systemu sterowania.
centrala sterowania rozjazdami i semaforami jest lokalna i wyspowa (moduł wykonawczy). Natomiast warstwa wizualizacyjna i interfejs jest sieciowany bo musi korzystac np z dziennika ruchu. I to ta warstwa straciła komunikację z systemem sterowania. W takiej sytuacji upewnia sie na gruncie stan rozjazdów lub je fizycznie blokuje i prowadzi sie ruch w tzw “zapowiadaniu telefonicznym” czyli na odstep miedzy posterunkami ruchu. Kazdy pociag musi byc telefonicznie potwierdzony ze dojechał do kolejnej stacji.
i taka ciekostka ze złozył sie tylko NOWY “cyberguard” Ebilock 950 podczas gdy stare Ebilock 850 np LCS Błonie bez problemu działały
” te systemy są wyspowe i nie są ze sobą powiązane sieciowo”
No i co z tego, systemy do sterowania wirówkami w Iranie też były …
“padł NTP z którego korzystały LCS”
Strzał w dychę, po co hackować LCSy skoro można ubić ich SPOF
” podobne problemy oprogramowanie Alstomu wygenerowało w innych krajach”
Rykoszet?
Uwielbiam teorie spiskowe i może przeczytamy o tym coś więcej za kilka lat.
Dla osób które już klepią komentarz “puknij się w głowę zje***” polecam lekturę:
“Odliczając do dnia zero. Stuxnet, czyli prawdziwa historia cyfrowej broni”
Autor: Kim Zetter
Nie każdy chłop z widłami to Posejdon i nie każda awaria systemu informatycznego to atak hackerski. Komputerowe systemy sterowania ruchem kolejowym, zgodnie z normami CENELEC (Europejski Komitet Normalizacyjny Elektrotechniki) projektowane są jako tzw. systemy bezpieczne, co oznacza, że każda anomalia rozpoznana przez system (skok napięcia, konflikt zegara czasu, itd.) automatycznie powoduje jego przejście w tzw. “stan bezpieczny” w działaniu urządzeń (jego wyłączenie), czyli semafory będą wskazywać sygnał „stój” i brak możliwości sterowania systemem (przede wszystkim bezpieczeństwo ludzi). Komputerowe systemy sterowania ruchem kolejowym nie posiadają dostępu z Internetu ani innej, zewnętrznej sieci teleinformatycznej, gdyż pracują one w sieciach zamkniętych zgodnie z definicją normy PN-EN 50159. Komputerowe systemy sterowania ruchem kolejowym mogą być dopuszczone do eksploatacji tylko gdy posiadają świadectwo dopuszczenia do eksploatacji wydane przez Prezesa Urzędu Transportu Kolejowego, czyli jest to de facto certyfikacja bezpieczeństwa, co zaprojektowano w nowej UKSC. Prawa własności do oprogramowania posiada tylko producent systemu, a użytkownik tylko eksploatuje go na zasadach udzielonej licencji, dlatego to producent ponosi odpowiedzialność za prawidłową jego pracę.
Czyli jak zwykle gowniany kod , napisany na kolanie przez studenta albo wysokiej klasy inzyniera z subkontynentu.
Metodologia cziper faster better zabije na predzej niz myslimy.
Czy osoby odpowiedzialne wyciągną może właściwe wnioski i przestana w przetargach publicznych brać pod uwagę firmy zatrudniające tania sile robocza lub outsource’ująca zadania bo sama nie ma zasobów napisania kilkuset linii kodu uwzględniających wszelkie możliwe scenariusze?!
“Problem z formatowaniem czasu” – chłopcy i dziewczęta radośnie bawiący się w tworzenie oprogramowania zapominają (albo nigdy nie wiedzieli) o elementarnych sprawach. Informację o czasie można przekazywać między systemami bez jakiegokolwiek formatowania. Ale to chyba za duże wymaganie dla generacji pokemonów.
To już nawet nie chodzi o to, że państwo z dykty tylko o to, że cały świat powoli robi się z dykty. Wszystkie państwa i firmy informatyzują co się da a jednocześnie to wszystko jest tak dziurawe, pokraczne, niestabilne, nieprzemyślane i nieprzetestowane że aż w pięty szczypie. Powstają monstrualne systemy nadzorujące wszystko i wszystkich a potem okazuje się, że – obrazowo mówiąc – ktoś coś zalepił tymczasowo gumą do żucia i tak już zostało bo w momencie odbioru wszystko działało.
Ja widze dwa glowne (bezposrednie) powody:
1. Przerosniete ego kierownictwa, manifestujace sie w generalnym niedocenianiu kompetencji technicznych co konczy sie wciskaniem rodziny/kolegow na wysokoplatne stanowiska czy obnizanie warunkow (placy) na innych orginalnie drogich stanowiskach i zatrudnianie tam przyslowiowej Pani Jagody (swoja droga bogu ducha winnej, bo placa powinna odpowiadac pracy – a informatyk 1000PLN/160h moze komputery przenosic, pakowac, oklejac lub sprawdzac czy prosto stoja…)
2. Podobnie ludzie decyzyjni nie widacy sprzecznosci w oczekiwaniu zeby pracownik byl wystarczajaco inteligentny i wyedukowany zeby poprawic wydajnosc algorytmu o 20%, algorytmu ktoremu jacys naukowcy dedykowali pare lat swojego zycia, o np. 20% a jednoczesnie mial problem z liczeniem na poziomie “na palcach” jesli idzie o czas, zarobki i jego wlasne wydatki czy ewentualnie nie jest w stanie ogarnac prostackiej wymowki…
Tak ze swojego podwórka 1 stycznia 2010 roku wszystkie urządzenia taśmowe pewnego producenta zgłosiły błąd, że postarzały się o 6 lat i domagały się natychmiastowego czyszczenia, poza tym wszystkie raporty z wykonywania kopii zapasowych pokazywały właśnie rok 2016. Co się okazało, producent w swoim mikrokodzie liczył datę od 2000 roku, w latach 2000-2009 wszystko było ok. Natomiast w roku 2010, okazało się, że pomieszał zapis dziesiętny z heksadecymalnym, 10 w hex to 16. Myślę, że tego rodzaju błąd wydarzył się w Ebilockach Bombardiera/Alstomu.
ktokolwiek cokolwiek teraz kupi od tej niepoważnej firmy? więcej dyrektorów, sekretarek ze znajomością dialektu kosmitów z marsa z 3 planety od 4 układu słonecznego, ale nie ma jakości produkt? PIĘKNE gratulacje dla wykonawcy węzła poznańskiego, thales, macie super konkurencje która się nie pier&^$%% :)
>> “Przyczyna leżała w oprogramowaniu komputera (hardware), nie w samym oprogramowaniu sterującym ruchem.” << Trochę to mętne. Oprogramowanie to nie hardware. Pod hardware można by jeszcze podciągnąć firmware, ale tu jest jednak mowa o "oprogramowaniu". Czyli jakiś ordynarny bug, bo oszczędzono na pokryciu scenariuszowym w testach (być może nawet na poziomie unit testów, co byłoby karygodne w tego typu systemie).
Pasowało by mi to na błąd w oprogramowaniu mikrokontrolera. Tu łatwiej o “przepełnienie licznika” czy obcięcie najbardziej znaczących bitów przy jakichś operacjach arytmetycznych. Software może siedzieć fizycznie w jednej kości z mikrokontrolerem, więc jest prawie jak hardware :)
To ja zadam takie pytanie:
Jeśli każdy odseparowany LCS ma wbudowany serwer NTP, to gdzie, jak i z czym ten serwer
NTP się synchronizuje?
I jak się synchronizuje, jeśli nie ma dostępu do sieci?
Przez tam-tamy? GPS? DVB-T? DAB? LTE?
W każdym cyfrowym sygnale są znaczniki UNIX time, więc to chyba nie jest problem walidacji czasu tylko błędnego czasu podanego ze źródła synchronizacji, to nie musi,
ale może być bardzo groźny atak.
Swoją drogą, takie ważne systemy muszą mieć wbudowany sprzętowy RTC, jeśli nie mają poprawnej komunikacji z nadrzędnym NTP, to i tak powinny wiedzieć, która godzina.
Lepiej też, żeby nie używały starego, dziurawego NTP, tylko nowszego protokołu NTS chronionego TLSem, a jeśli czas biorą z innego medium np GPS, to też trzeba przeanalizować bezpieczeństwo tego źródła czasu.
Z resztą z GPSem i metodami satelitarnymi radzę uważać, aktualizacje bezpieczeństwa w sztucznych satelitach to dosyć skomplikowana sprawa.
Pozdro
“W każdym cyfrowym sygnale są znaczniki UNIX time”
Nieprawda. Protokół NTP nie korzysta z Unix time.
Ja osobiście mam serwery NTP odseparowane od Internetu :) GPS z wyjściem PPS + komputer i masz serwer NTP Stratum 1 odseparowany od Internetu. Można też użyć DCF’a… Ba – jak komuś nie zależy na dokładności to przecież nic nie stoi na przeszkodzie żeby zrobić serwer NTP oparty o zegarek na płycie głównej…
piękne preludium przed 19 stycznia 2038 :)
Dokładnie to samo, miałam na myśli :-)
Zapewne po tym incydencie pojawi się nowy typ komunikatu dla pasażerów ::
Kliencie, przed podróżą prosimy się upewnić czy serwer NTP działa poprawnie.
Dzisiaj w Pulsie Biznesu pojawił się artykuł o tej awarii.
https://www.pb.pl/rosyjski-cien-kolejowej-awarii-1144811
Niestety nie mam pełnego dostępu do tekstu, a PB czasami szuka sensacji na silę, ale w zajawce opisali to w ten sposób:
Rosyjski cień kolejowej awarii
Awarię na kolei, która wywołała ogromne zamieszanie, szybko wziął na siebie Alstom, producent systemu. Szybko też okazało się, że za komponenty do niego odpowiada firma z Rosji.
Przeczytaj artykuł i dowiedz się:
Jaka spółka jest dostawcą komponentów do systemu, który w czwartek uległ awarii
Dlaczego te komponenty są newralgiczne z punktu widzenia cyberbezpieczeństwa
Czy PKP PLK miały wiedzę o podwykonawcach newralgicznego systemu
Czy awaria, która według deklaracji miała charakter globalny, wystąpiła też w Rosji
W poniedziałek padł system sterowania w Madrycie na stacji Chamartín. To taki dworzec na północy na którym startują pociągi średniego i dalekiego zasięgu po liniach tradycyjnej prędkości oraz przez którą przejeżdżają praktycznie wszystkie linie lokalne Efekt to masakra całej lokalnej kolei. Powód ten sam co w Polsce.
System NTP zsynchronizował zapad systemu ;-). Skoro to ma sterować ruchem pociągów to pewnie obsluga czasu jest ważna a program jak się zawiesi to może jakiś mechanizm bezpieczeństwa wyłącza sterowanie bo lepiej wolniej i ręcznie niż ryzykować zderzenie.
Z ciekawostek jak coś może się wysypać – mamy placówkę gdzie kupili cyfrowy RTG jednak z oprogramowaniem uniwersalnym – nie obsługującym polskiego PESELU. Jest pole – klucz główny nr pacjenta i tam użytkownicy wpisują PESEL. Problem jest z tym że jak dany pacjent przyjdzie 2 razy to system nie przyjmie dwóch identycznych rekordów. Użytkownicy zaczeli więc dopisywać n spacji i jakiś znak, poza widocznością pola. No i kiedyś okazało się że ; na końcu wywalał system, nie widać tego bo znak jest poza polem ;-).
Ale pomysl ile kilobajtow udalo sie oszczedzic producentowi na kolumnie klucza…
Chyba sporo nie wiemy skoro najprostsza implementacja bezpiecznego czasu kosztuje kilka dolarów. Gdyby system był zaprojektowany w bezpieczny sposób NTP używany byłby tylko do AKTUALIZACJI czasu i nie byłby krytycznym elementem systemu. Ale żeby tak coś zaprojektować potrzebny jest RTC zasilany mała bateryjką – taką jak z BIOS miał już 30 lat temu. Dzięki temu NTP może być niedostępny nawet przez kilka tygodni, ale wadą jest to że co kilka lat ktoś fizycznie musi wymienić baterię w każdym LCS.
Tak więc awaria sugeruje że system celowo był zaprojektowany jako “defective by design” i centralizacja NTP była wymagana aby uzależnić całą infrastrukturę kolejową od jednej firmy i firma ta może “wyłączyć” cały ruch kolejowy na swoich “LCS” jednym guzikiem.
Inna sprawa czy ten guzik nacisnął się celowo, czy ktoś mu pomógł.
Z tego co rozumiem, bateria jest potrzebna tylko kiedy system jest odlaczony z pradu co poderzewam, ze w systemie kontroli ruchu raczej sie nie zdarza. Do tego przelanczanie na system awaryjny czy miedzy dwoma zrodlami dalo by sie ogarnac jakims kondensatorem.
Ale nędza, niestety…
W Standardach Technicznych PLK zapisało:
3. Zapisywany obraz powinien być uzupełniony stemplem czasowym o rozdzielczości 1s.
W celu eliminowania błędu stempla czasu zaleca się, aby data i czas rejestratora były
synchronizowane z czasem państwowym pozyskiwanym z serwera czasu przez sieć LAN
z użyciem protokołu NTP albo z odbiornika DCF lub też z odbiornika GPS/Galileo,
z zapewnieniem automatycznej zmiany czasu z letniego na zimowy.
A Bombardier w specyfikacji zapisał:
9. Zapisywany obraz powinien być uzupełniony stemplem czasowym o rozdzielczości 1s.
W celu eliminowania błędu stempla czasu zaleca się, aby data i czas rejestratora były
synchronizowane z czasem państwowym pozyskiwanym z serwera czasu przez sieć LAN
z użyciem protokołu NTP lub z centralki DCF, z zapewnieniem automatycznej zmiany
czasu z letniego na zimowy.
[…] 17 marca nastąpiła cała seria awarii centrów sterowania ruchem kolejowym, dość szybko pojawiły się podejrzenia, że mogą one być spowodowane cyberatakiem. Tymczasem […]