29/6/2020

W dzisiejszych czasach trudno spotkać firmę, która nie poczyniła żadnych inwestycji związanych z cyberbezpieczeństwem. Praktycznie wszyscy dostrzegli potrzebę ochrony i kupili jakieś produkty, które dają ochronę lub przynajmniej złudzenie ochrony. Firewalle, UTM-y Next, Generation Firewalle, Antiwirusy, Antimalware, NAC, Antispam, DLP, IPS, WIPS, itd… Wszyscy producenci rozwiązań obiecują, że ich rozwiązania skutecznie zabezpieczą sieć użytkowników i zasoby. Tutaj przychodzi pora na refleksję: czy obietnice producentów będą spełnione?
Należy przyjąć za pewnik, że każde narzędzie wymaga właściwej architektury, właściwego użycia, zatem istotna jest konfiguracja – właściwa konfiguracja. W takim momencie pojawia się istotne pytanie:
Czy po inwestycji w rozmaite systemy ochrony jesteśmy naprawdę bezpieczni? Czy moje systemy są kompletne?
Sprawdźmy to wspólnie.
Weryfikacja cyberbezpieczeństwa
Oczywiście można przeprowadzić walidację poziomu bezpieczeństwa dla każdego z komponentów prowadząc powtarzane cyklicznie audyty, zarówno wewnętrzne, jak i outsourcowane. Audyt konfiguracyjny, audyt architektury, automatyczne testy podatności, testy penetracyjne kierowane na konkretne aplikacje i systemy pozwolą uszczelnić zabezpieczenia. Te operacje należy powtarzać cyklicznie. Co ile? Najlepiej raz na 3 miesiące, czy chociaż raz na pół roku. Tutaj jednak pojawia się pytanie: czy wiemy (albo skąd wiemy), że w danym momencie nasze systemy nie są atakowane, czy nie zostały już częściowo przejęte? I tak właśnie dochodzimy do tematu, którym chcemy się zająć w niniejszym artykule: stały monitoring bezpieczeństwa i organizacja zespołu zajmującego się takimi zagadnieniami, czyli Security Operations Center, w skrócie SOC.
&Nbsp;
Co to jest SOC: czyli Security Operations Center
Security Operations Center to zespół monitorowania i reagowania na zagrożenia bezpieczeństwa, czyli grupa ludzi, która przy użyciu dedykowanych narzędzi na bieżąco wykrywa zagrożenia i anomalie oraz próbuje ograniczać ich wpływ na środowisko IT:
- analizując dane (logi, flowy) z infrastruktury w celu wykrycia zdarzeń cyberbezpieczeństwa,
- stale monitorując podatności bezpieczeństwa wstępujących w naszych zasobach,
- monitorując bazy podatności i zagrożeń (Threat intelligence),
- reagując na zdarzenia z zakresu cyberbezpieczeństwa,
- raportując zdarzenia,
- współpracując i z IT i biznesem.
Dlaczego warto wdrożyć SOC?
Powodów jest co najmniej kilka.
- proaktywne wykrywanie zagrożeń. Średni czas wykrycia włamania do zasobów IT w USA to 206 dni,
- świadomość zagrożeń, aby dostosować zabezpieczenia zanim dojdzie do niebezpiecznej sytuacji,
- zarządzanie podatnościami, aby eliminować je możliwie wcześnie,
- bezpieczeństwo reputacji firmy,
- stałe testowanie i monitorowanie cyberbezpieczeństwa,
- zarządzanie logami, aby przechowywać, ewidencjonować i mieć dowody na wszystko.
Jak zrobić taki SOC i ile to kosztuje?
To zależy od wielu czynników. Można SOC wybudować u siebie, tzn. zatrudnić specjalistów, zbudować stosowne rozwiązania techniczne. Można traktować takie rozwiązanie jako usługę dostarczaną przez zewnętrznych partnerów. Można podejść do tego hybrydowo, tj. częściowo realizować to wewnętrznie, częściowo obsługiwać to w formie zewnętrznych usług. Koszt takich rozwiązań zależy od komplikacji naszych rozwiązań IT i ich rozmiaru, trybu w jakim chcemy powołać SOC do działania, czy będzie to działanie całodobowe, czy działanie tylko w wybranych godzinach. SOC powinien być szyty na miarę potrzeb i możliwości.
Nasze doświadczenie rynkowe pokazuje, że w znakomitej większości średnich firm aktywny monitoring bezpieczeństwa nie istnieje jako takowy. W wypadku firm zatrudniających kilku specjalistów IT trudno mówić o tworzeniu zespołu dedykowanego tylko do celu monitorowania i reagowania na incydenty bezpieczeństwa sieciowego. Polecam zatem uwadze nasze usługi w zakresie wsparcia w monitoringu bezpieczeństwa oraz narzędzia minimalizujące wkład pracy przy monitorowaniu bezpieczeństwa.

Narzędzia służące do tworzenia środowiska SOC
Z jakich komponentów technicznych powinien (idealistycznie) składać się zespół monitorujący bezpieczeństwo sieciowe? Narzędziami, których powinno się użyć budując takie centrum bezpieczeństwa są:
- Security Information and Event Management SIEM,
- NetFlow collector & analyzer,
- narzędzia do śledzenia i analizy propagacji zagrożeń w sieci,
- narzędzia do analizy malware tzw. Sandbox,
- dostęp do bazy zagrożeń: Threat intelligence oraz bazy tzw. Indication of Compromise,
- skanery podatności: Vulnerabilities scanners,
- system organizujący działania związane z odpowiedzią i reakcją na incydenty bezpieczeństwa tzw. SOAR,
- system przechowujący bazę wiedzy
Postarajmy się prześledzić kilka przykładowych rozwiązań wraz z ich możliwościami
Security Information and Event Management
Security Information and Event Management, to system, który w dużym skrócie, zbiera dane z wielu źródeł w postaci logów z różnych systemów, parsuje i normalizuje te dane, aby w kolejnym kroku przeprowadzić analizę tych danych oraz ich korelację i na tej podstawie wygenerować zdarzenia bezpieczeństwa.
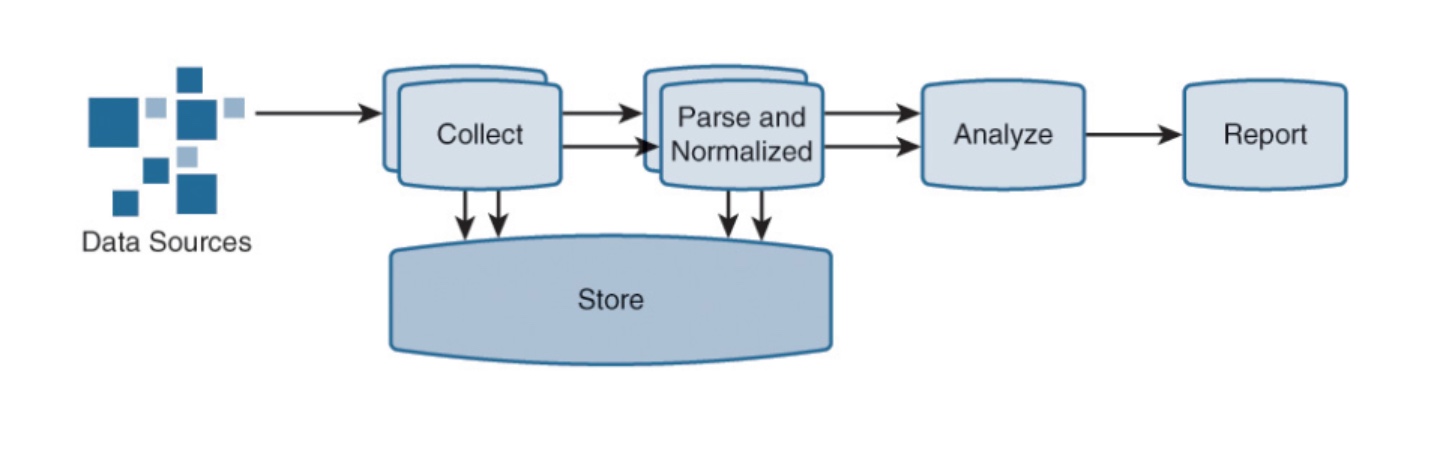
Jakie dane wprowadzane są do SIEM:
- logi: syslog z komputerów, serwerów, aplikacji, urządzeń sieciowych, urządzeń security,
- dane o działaniu sieci, przesyłanych danych: tzw. Flowy: NetFlow Sflow, Jflow itp.,
- komunikacja sieciowa z urządzeń na których nie można skonfigurować żadnej technologii służącej do generowania informacji o ruchu sieciowym: Span porty,
- IDS, host IDS.
Oczywiście zdawałoby się, że im więcej danych tym lepiej, większa szansa na odkrycie ciekawych zdarzeń. Z jednej strony tak, ale pozyskując dane ze wszystkich źródeł można łatwo doprowadzić do przesytu informacyjnego, w takiej sytuacji trudno będzie analizować i przetwarzać wszystkie pojawiające się zdarzenia.
Dane są następnie parsowane tj. dostosowywane do jednolitego formatu. Różny format logów przesyłanych przez różne urządzenia wymaga odpowiedniego odczytania informacji i takiego ich przetworzenia, aby trzymane dane były zorganizowane w jednolity sposób. Rozwiązania SIEM oczywiście mogą posiadać stosowne gotowe do użycia parsery, jednak zazwyczaj także istnieje konieczność stworzenia dedykowanych parserów dla konkretnych, indywidualnych dla organizacji potrzeb.
Powyższe działanie pozwoli na analizowanie danych i ich korelacje, czyli łączenie w związki przyczynowo skutkowe świadczące o wystąpieniu określonych zagrożeń. Korelacje także występują w wariantach pudełkowych tj. gotowych „od ręki”, ale istotna jest możliwość tworzenia własnych związków logicznych. Reguły korelacyjne prowadzą do powstania zdarzeń (events), czyli istotnych z perspektywy bezpieczeństwa sytuacji.
SIEM-ów na rynku jest wiele, można powiedzieć, że każde potrzeby zostaną zaspokojone, a my chętnie pomożemy w wyborze narzędzia dostosowanego do potrzeb użytkownika.
Poniżej przedstawiamy jedno z wielu porównań dostępnych w internecie. Podsumowanie tego porównania dostępne jest w formie tabeli:
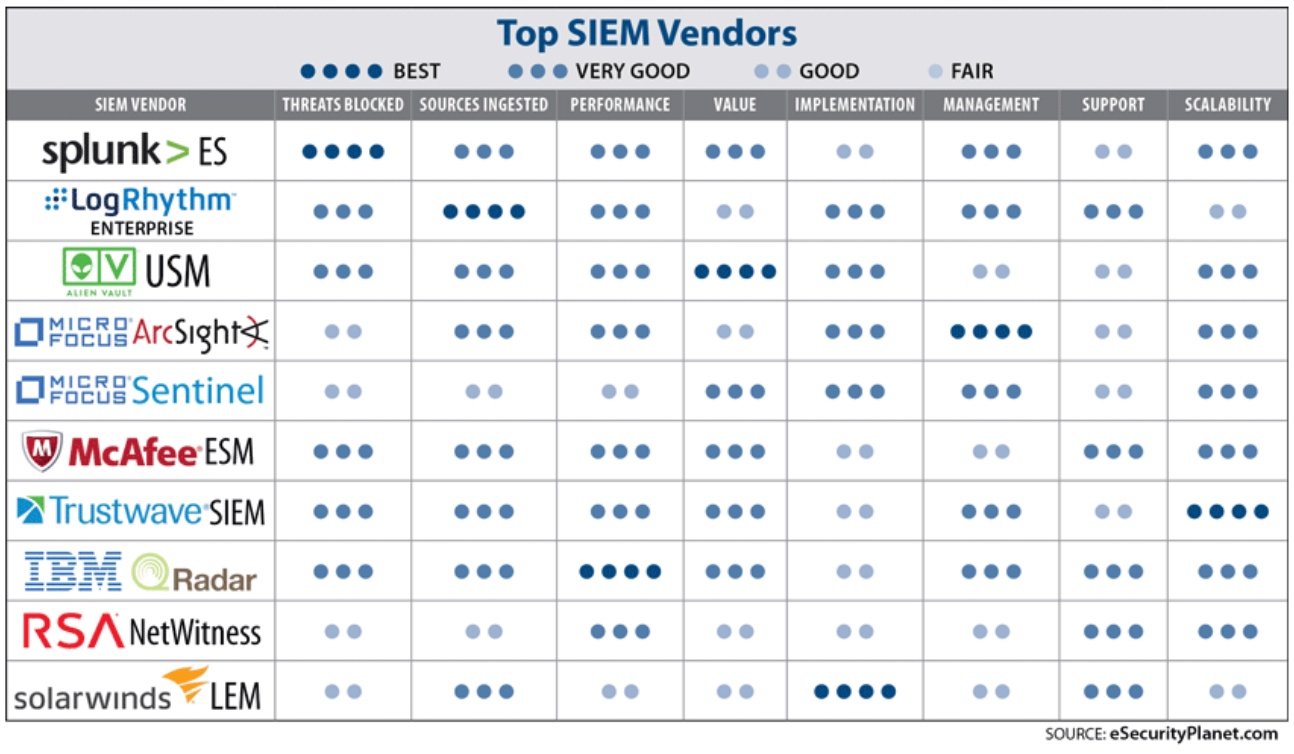
Omówmy pokrótce dwa z dostępnych na rynku rozwiązań:
Alienvault OSSIM
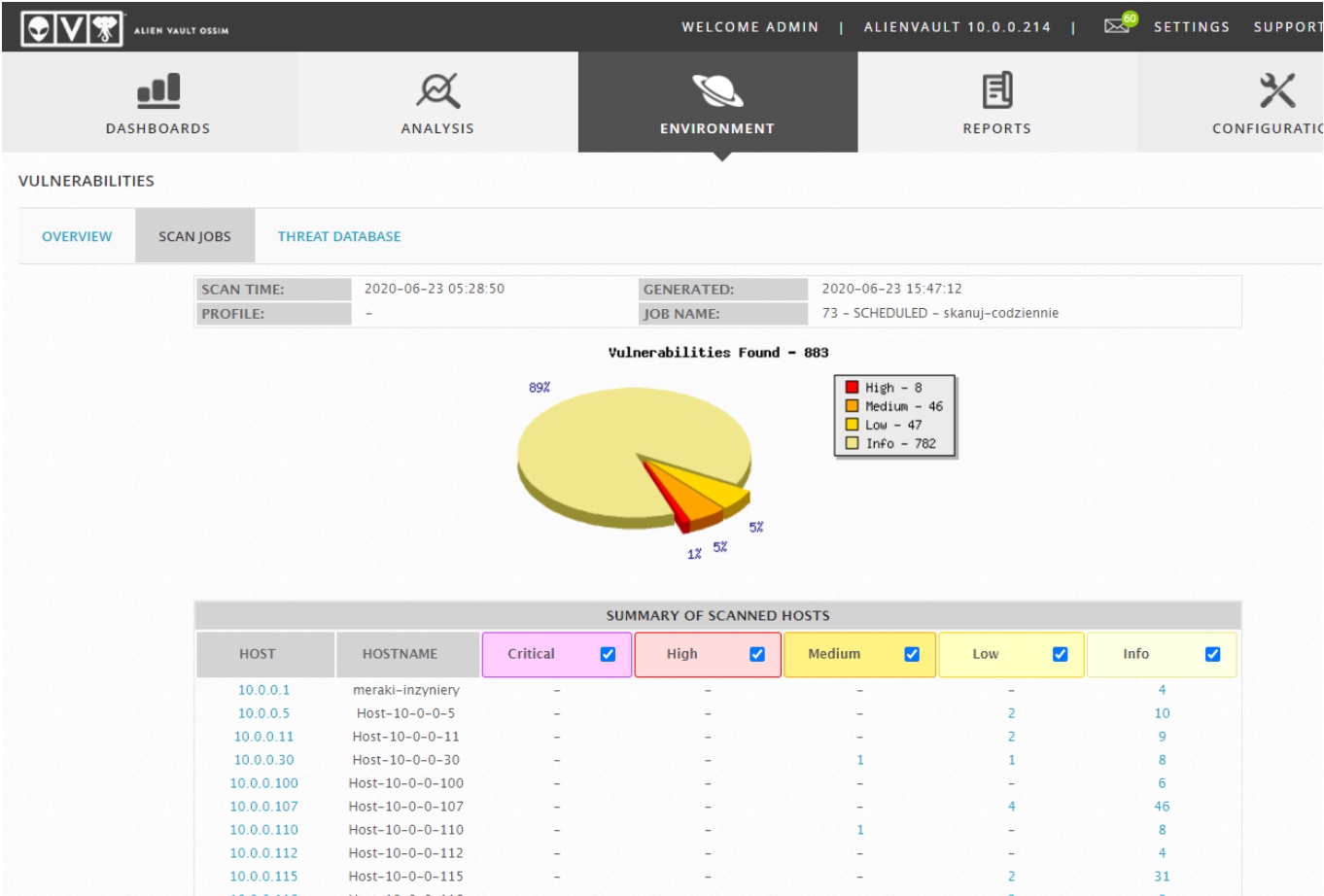
Poniżej prezentujemy kilka kluczowych możliwości systemu Alienvault OSSIM. OSSIM ma tę jakże znaczącą zaletę, że posiada relatywnie dużą ilość parserów oraz dysponuje własną dostępną bazą zagrożeń: Alienvault OTX. Korzystne jest także to, że OSSIM ma wbudowaną opcję użycia skanera podatności Openvas. Poniżej pokazano rezultat skanowania openvas-em monitorowanych przez OSSIM zasobów.
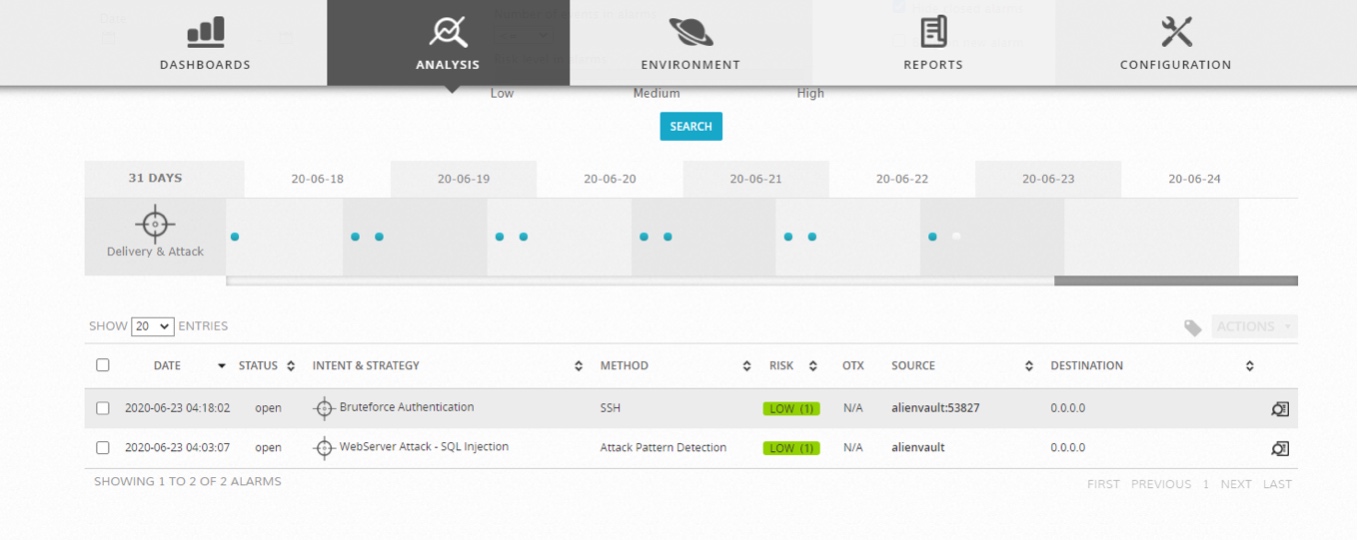
Za pomocą OSSIM możemy wykrywać zdarzenia różnego typu, czy to takie, które korzystają ze wbudowanych reguł, czy też takie, które samodzielnie skonfigurujemy.
Poniżej pokazano zdarzenie, które zostało wzbudzone przez atak typu brute force na serwer dostarczający logi do OSSIM.
Jako kolejny przykład pokazujemy event, który generuje OSSIM w wypadku wystąpienia ataku na protokół ARP: ARP spoofing
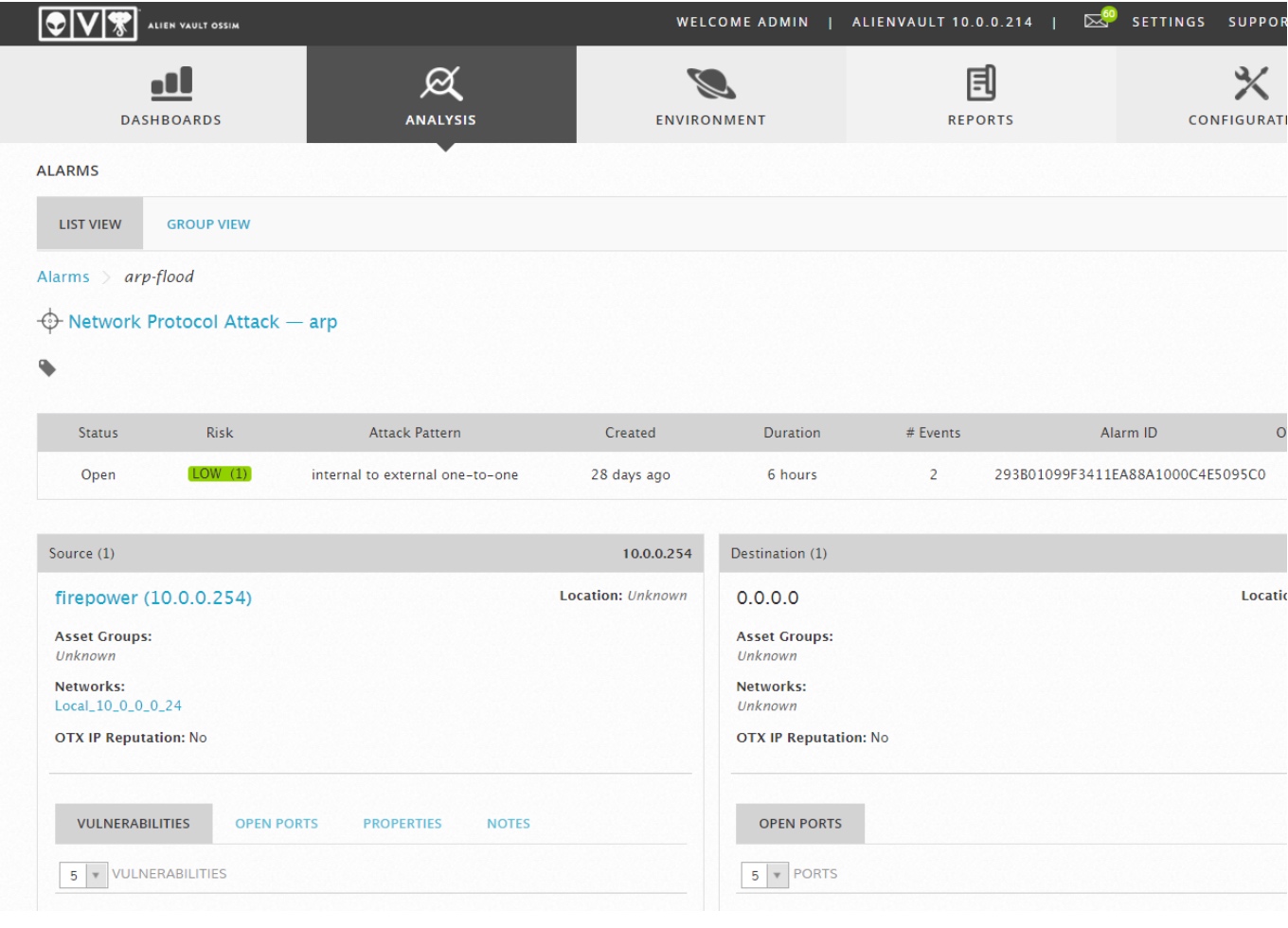
System po „wyjęciu z pudełka” wykrywa szereg zdarzeń, i są to:
- skanowania,
- ataki na aplikacje web (XSS),
- ataki na bazy danych (SQL injection),
- ataki typu denial of service,
- kilka ataków związanych z wykryciem działalności malware lub ransomware (ruch do adresów CNC itp.).
Pozwala oczywiście także na tworzenie własnych regułek, jednak należy zauważyć, nie jest to zadanie specjalnie przejrzyście zorganizowane.
Alienvault pozwala na korzystanie z bogatej listy tzw. data sources, jak na przykład anomalie sieciowe pokazane na zrzucie ekranowym poniżej.

Na podstawie tych zdarzeń pochodzących z tzw. data sources możemy kreować polityki definiujące jak klasyfikujemy dane zdarzenie w konkretnych warunkach (np. kierowane na konkretny cel).
Podsumowując fajne w OSSIM są:
- koszt (bo OSSIM jest darmowy),
- integracja ze skanerem podatności,
- baza parserów,
- baza zdarzeń gotowych i korelacji.
Trochę mniej przyjemne są:
- interfejs – momentami o średniej przejrzystości,
- giętkość tworzenia własnych wzorców określających zdarzenia interesujące z perspektywy bezpieczeństwa.
Warto nadmienić, że OSSIM pozwala na zbieranie danych z protokołu NetFlow, jednak zdarzenia które możemy generować na podstawie obserwacji NetFlow są dość ograniczone.
Splunk w zastosowaniu jako SIEM
Ciekawą alternatywą dla Alienvault jest system Splunk wykorzystywany jako SIEM. Splunk jest narzędziem o szerszych możliwościach wykorzystania niż jedynie system SIEM. Jest w istocie narzędziem analitycznym, który zbierając dane z wielu źródeł maszynowych służy do obróbki tych danych dla celów przykładowo związanych np. z analityką biznesową, utrzymaniem systemów, DevOPS, IT operations.
Piękno możliwości definiowania zapytań do pobranych danych objawi nam się w momencie, gdy będziemy chcieli definiować własne korelacje i własne zdarzenia, które traktujemy jako problemy cyberbezpieczeństwa.
Przy pomocy języka zapytań Splunk można poprosić o odpowiedź na skomplikowane zapytania dotyczące zebranych danych.
Poniżej najprostsze zapytanie statystyczne:

A poniżej już coś minimalnie bardziej złożonego, bazującego na pobraniu danych NetFlow do Splunk np. analiza statystyczna działania protokołu ARP w sieci:
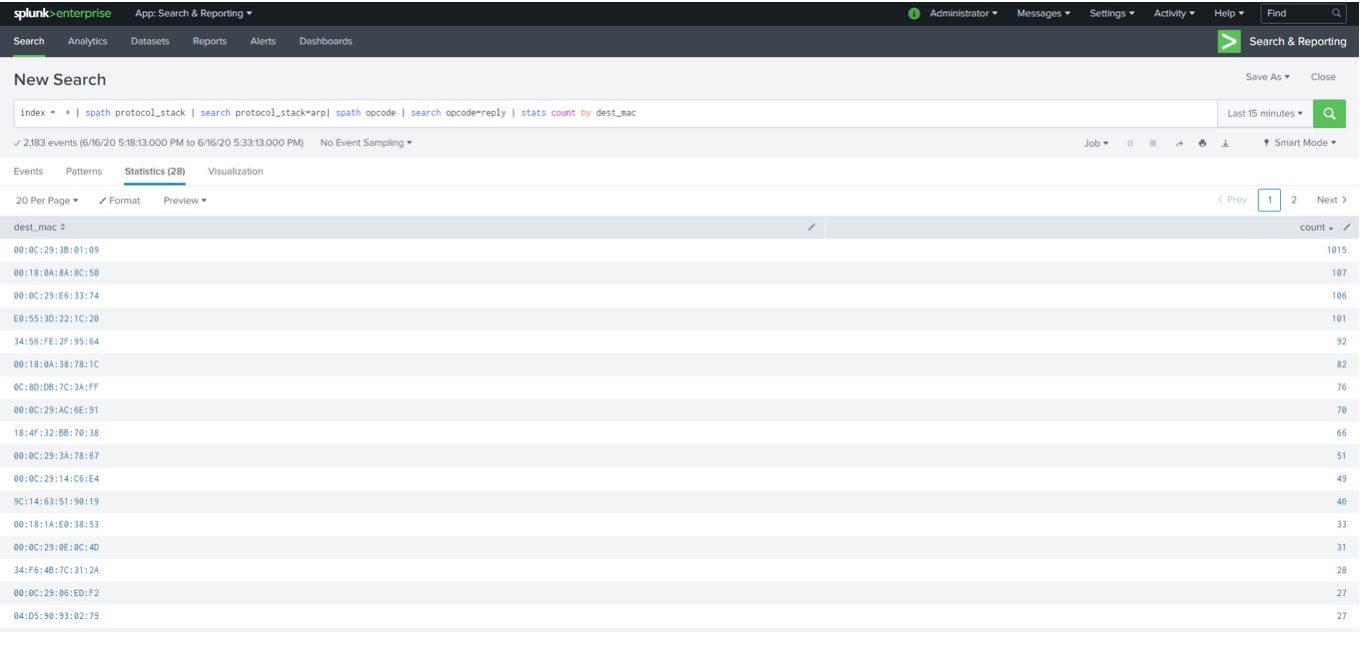
W zasadzie Splunk bez jakiejkolwiek wbudowanej wiedzy o zagrożeniach bezpieczeństwa po zasileniu w dane NetFlow, czy w dane pochodzące z logów, można wysiłkiem tytanicznej pracy uczynić systemem SIEM.
Na szczęście z pomocą przychodzą dodatkowe aplikacje Splunk jak Security Essentials i Enterprise Security. Ta pierwsza jest darmowa i pozwala na wychwytywanie podstawowych zdarzeń z zakresu cyberbezpieczeństwa.
Próbkę tego, co możemy w Splunku Security Essentials osiągnąć, widzimy na poniższym screenie.

Wykrywane zagrożenia można także przeglądać wg metodologii Mitre ATT&CK

A tutaj przykład wykrytego zdarzenia typu logowanie brute-force, najpierw zapytanie
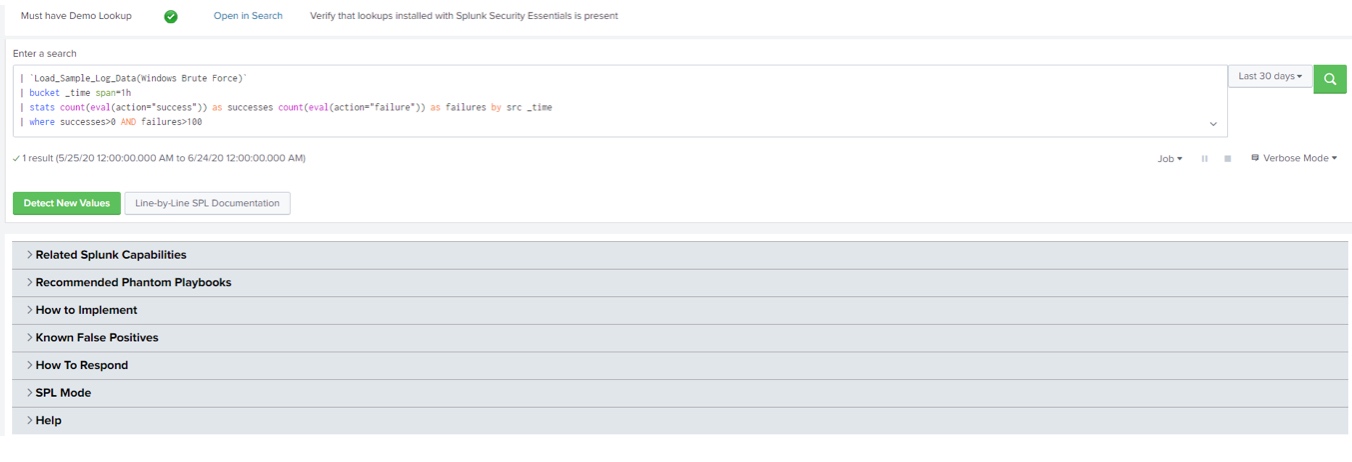
a zaraz potem dane pozyskane poprzez zapytanie:

Kończąc pobieżnie dotknięty temat SIEM warto zauważyć, ze każdy SIEM wymaga dogłębnego strojenia, określenia jakie zdarzenia chcemy obserwować. Wiedza taka może wynikać z określenia priorytetowych zasobów dla organizacji, analizy ryzyka, analizy zagrożeń.
Możemy jako przykłady zdarzeń, które warto dostrzegać przy użyciu SIEM, podać poniższą listę. Niestety z racji obszerności zagadnienia, jest to lista zdecydowanie niekompletna, ale po pełnię wiedzy zapraszam do kontaktu z nami.
- Authentication activities: logowania w dziwnych porach, brute force,
- Information Theft: DLP, duże rozmiary danych wysyłanych z naszej sieci,
- Vulnerability Scanning: skanowanie naszej sieci w celu wyszukania podatności,,
- Intrusion Detection and Infection: IDS, antimalware, antivirus: zdarzenia generowane przez systemy AV,
- System Change Activities: zmiany konfiguracyjne w systemach kluczowych, zmiany prowadzone w dziwnych godzinach,
- ruch administracyjny do naszych zasobów pochodzący spoza sieci administracyjnych,
- ataki na protokoły sieciowe Mac Flooding, ARP Spoofing itp.,
- Ataki brute force na hasła,
- ruch tunelowany np. przez DNS,
- komunikacja przez system ToR,
- ataki na aplikacje web,
- ataki na bazy danych.
Wykorzystanie informacji o ruchu sieciowym dla potrzeb analizy bezpieczeństwa
Dane jakie przesyłamy przez sieć, kierunki naszej komunikacji, uśredniony wolumen komunikacji i charakterystyczny statystycznie dla danej maszyny, specyficzna komunikacja, pozwalają wykrywać zagrożenia.
Co jest do tego potrzebne: NetFlow oraz specyficzny collector, który interpretuje pozyskane dane w określony sposób. Spróbujemy takowe narzędzie pokazać na przykładzie rozwiązania Cisco Stealthwatch w wariancie Cloud.
Rozwiązanie składa się z sondy umieszczanej w sieci monitorowanej oraz kolektora znajdującego się w chmurze. Dla tych, którzy boją się chmury – istnieje oczywiście także wersja On Premise, czyli taka, w której praktycznie cała logika zamyka się w sieci monitorowanej. Sonda otrzymuje tzw. flowy z urządzeń sieciowych.
Czym są Flowy?
Flowy są formą opisu ruchu sieciowego przesyłanego przez urządzenie bez przesyłania rzeczywistych danych. Znajdziemy więc we flowach informacje o źródle i celu komunikacji, portach zastosowanych, ilości danych itd. Na tej podstawie możemy w klasycznym wykorzystaniu budować statystyki, np. kto ile wysłał ruchu http, ile ruchu i jaki jest wysyłany do konkretnego serwera itd. W wariacie wykorzystania tego do celów ochrony przed zagrożeniami bezpieczeństwa proces jest trochę bardziej złożony i pozwala wykrywać przykładowo:
- stałe połączenia utrzymywane z wnętrza naszej sieci do urządzeń zewnętrznych,
- połączenia z urządzeniami z którymi wcześniej nie kontaktowaliśmy się,
- połączenia wykorzystujące relatywnie duże pasmo,
- połączenia z danymi niepasującymi do wykorzystywanego portu,
- komunikację z domenami znanymi jako potencjalnie niebezpieczne,
- komunikację z domenami założonymi przed chwilą,
- ruch z konkretnej maszyny odbiegający wolumenem czy charakterem od poprzednio obserwowanej charakterystyki w określonym interwale czasowym komunikacji.
Możliwości systemu są oczywiście dalece szersze. Lista powyższa pokazuje jedynie przykłady, które pozwalają dostrzec jak ciekawe obserwacje można poczynić traktując sieć jako sensor bezpieczeństwa.
Można oczywiście próbować wszystkie regułki zdefiniowane w ramach tego systemu wyklikać, przykładowo w rozwiązaniu Splunk, jednak działanie ręczne wymagać będzie dość sporej determinacji. Splunk ma rozwiązanie, które pozwala na wykorzystanie predefiniowanych reguł, i jest to Splunk UBA, jednak to rozwiązanie jest już także rozwiązaniem płatnym.
Ja polecam system Cisco Stealthwatch, który w zasadzie przy minimum konfiguracji będzie gotowy do zbierania danych i wykonywania analizy pod katem bezpieczeństwa. Zapraszam do kontaktu chętnie porozmawiamy o możliwościach wdrożenia rozwiązania.
Bazy zagrożeń: Threat intelligence
Istotna, z perspektywy monitorowania bezpieczeństwa, jest także bieżąca analiza pojawiających się zagrożeń – ocena czy wpływają one na monitorowane przez nas systemy. Przygotowanie stosownych reguł dla systemu SIEM tak, aby wykrywać nowe zagrożenia, wreszcie sugestie dla działów IT tak, aby uszczelniać systemy celem ich uodpornienia na nowe zagrożenia.
Istnieje wiele baz zagrożeń, część z nich jest płatna, część dostępna całkowicie za darmo. Bazy definiują różne aspekty zagrożeń, takich jak np. malware czy phishing.
Threat intelligence jako pojęcie należy interpretować jako źródło opisu mechanizmów, metod, dowodów oraz sposobów zwalczania zagrożeń cybersecurity.
Szukamy oczywiście źródeł maksymalnie wiarygodnych, a także często aktualizowanych. Listy źródeł publikujących informacje z kategorii Threat intelligence:
https://safebrowsing.google.com/
https://talosintelligence.com/vulnerability_reports
https://www.virustotal.com/
https://www.abuse.ch
https://otx.alienvault.com/dashboard/new
https://www.phishtank.com
Poniżej kilka zrzutów ekranowych pokazujących co znajdziemy w bazach Threat intelligence. Tutaj wygląd bazy Alienvault OTX
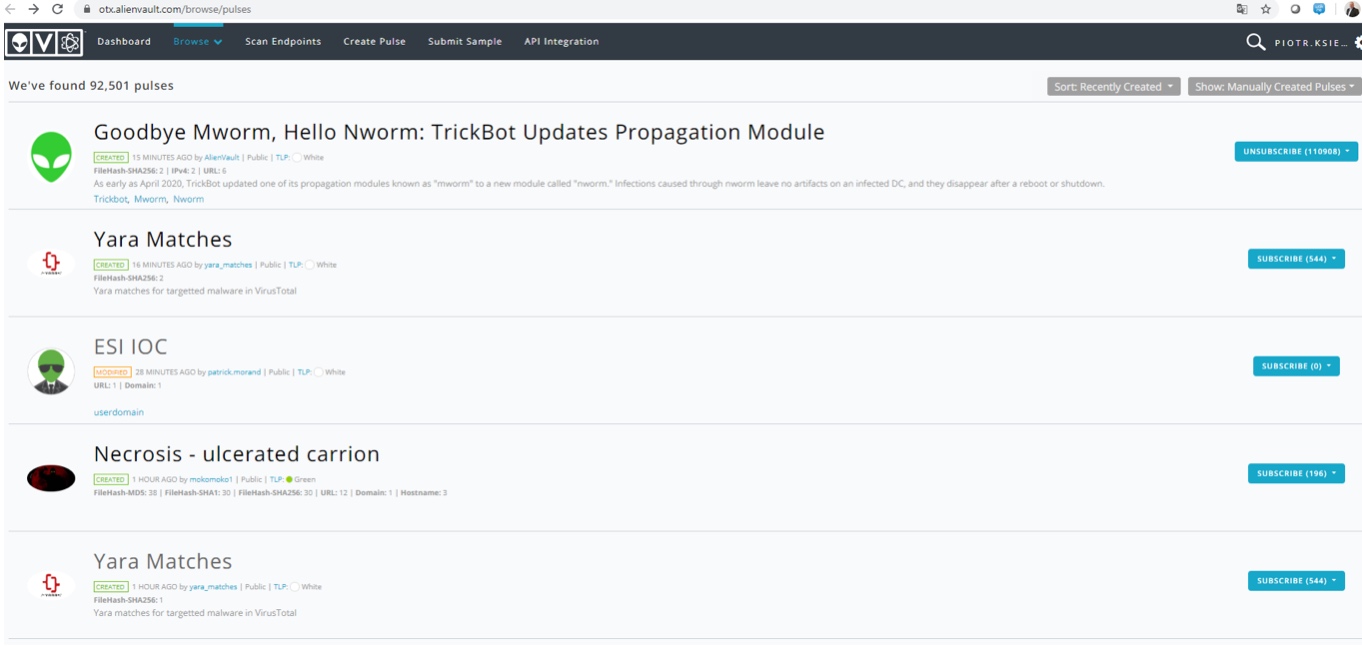

Bazy Threat intelligence, tak jak już powiedzieliśmy, mogą służyć do tworzenia nowych regułek SIEM czy nowych wskazań do konfiguracji urządzeń bezpieczeństwa. Jest to jednak także dobra baza do testowania naszych zabezpieczeń. Niewielkim nakładem pracy można skonstruować przy użyciu języków skryptowych tester sprawdzający nasze Next Generation Firewalle, naszą ochronę antimalware itd. Po szczegóły zapraszamy do nas:
Bazę zagrożeń wraz z ich opisem i klasyfikacją zawiera także narzędzie Cisco Threat Grid, które w istocie jest sandboxem, i które przybliżymy poniżej. Tutaj jedynie zrzut ekranowy z wszystkich zagrożeń opisanych i udokumentowanych przez Cisco.
Analiza plików z potencjalnymi zagrożeniami: sandboxing
Istotne z perspektywy działania monitoringu bezpieczeństwa jest także narzędzie służące do analizy plików z potencjalnymi zagrożeniami. Narzędzie, które pozwala pliki podejrzane w kontekście cybersecurity analizować, dając jednoznaczną odpowiedź czy dany plik klasyfikuje się jako zagrożenie, czy też nie. Narzędzie to jest często uruchamiane już na etapie analizy przesyłanej zawartości, na etapie filtrowania ruchu lub ochrony stacji końcowej, wtedy kiedy warstwa ochrony nie może samodzielnie podjąć decyzji o statusie bezpieczeństwa pliku.
Wyposażenie w sandbox jest kluczowe dla działu SOC. Pozwala on na analizę zdarzeń bezpieczeństwa już po ich wykryciu, a także na tworzenie nowych reguł dla systemów SIEM. W tych regułach możemy zawierać obserwacje poczynione za pomocą narzędzia sandbox.
Sandbox przeprowadza analizę statyczną oraz w szczególności dynamiczną plików.
Analiza dynamiczna to ni mniej, ni więcej tylko uruchomienie pliku z zagrożeniem w środowisku odizolowanym od środowiska produkcyjnego. Sandbox zbiera informację o zachowaniu pliku uruchamianego analizując modyfikowane pliki, modyfikacje rejestrów, operacje systemowe, połączenia sieciowe. Na podstawie zachowania pliku wydawany jest werdykt na temat pliku, jest on klasyfikowany jako zagrożenie lub jako bezpieczny.
Sandbox w oczywisty sposób współpracuje już na etapie ochrony z urządzeniami zabezpieczającymi nasze systemy takimi jak firewalle, ochrona poczty, ochrona antimalware. Wszystkie te systemy korzystają z sandboxa w sytuacji, gdy nie są w stanie autonomicznie ocenić bezpieczeństwa przesyłanych plików.
Jednocześnie jednak sandbox powinien współpracować z systemami SIEM poprzez wprowadzanie do systemu informacji o wskazaniach (np. komunikacji sieciowej lub operacji plikowych), które należy uznać za zagrożenia bezpieczeństwa i adekwatnie zaraportować.
Poniżej widzimy System Cisco Threat Grid w działaniu. Na screenach przedstawiona jest analiza działania jednego pliku wykonywalnego i podsumowanie definiujące czy plik jest szkodliwy czy też bezpieczny biorąc pod uwagę rozmaite testowane kategorie.
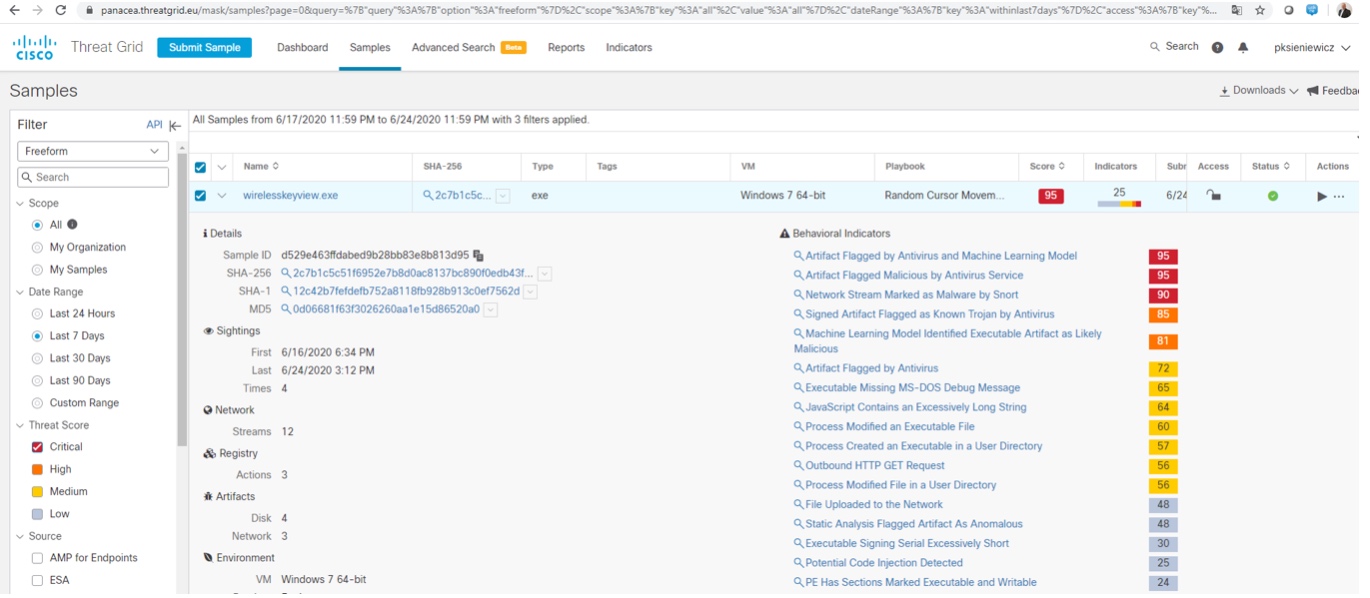
Dodatkowo można pozyskać pełen raport przedstawiający wykonywane testy oraz ich rezultaty. Raport przedstawia dokładnie:
- aktywność sieciową,
- działania na rejestrach systemowych,
- działania na plikach,
- uruchamiane procesy.

Dodatkowo można obejrzeć zrzut operacji sieciowych w formacie pcap, a nawet obejrzeć film z wykonywania analizowanego pliku na maszynie testowej.
Narzędzie do analizy propagacji zagrożeń w sieci
Jednym z zadań zespołu SOC jest analiza i odpowiedź na wykryte ataki sieciowe. Narzędziem, które może być przydatne w tym zadaniu jest system śledzący propagację malware w ramach sieci. Obserwacja taka pozwoli na skuteczne odizolowanie zainfekowanych maszyn i eliminację zagrożeń.
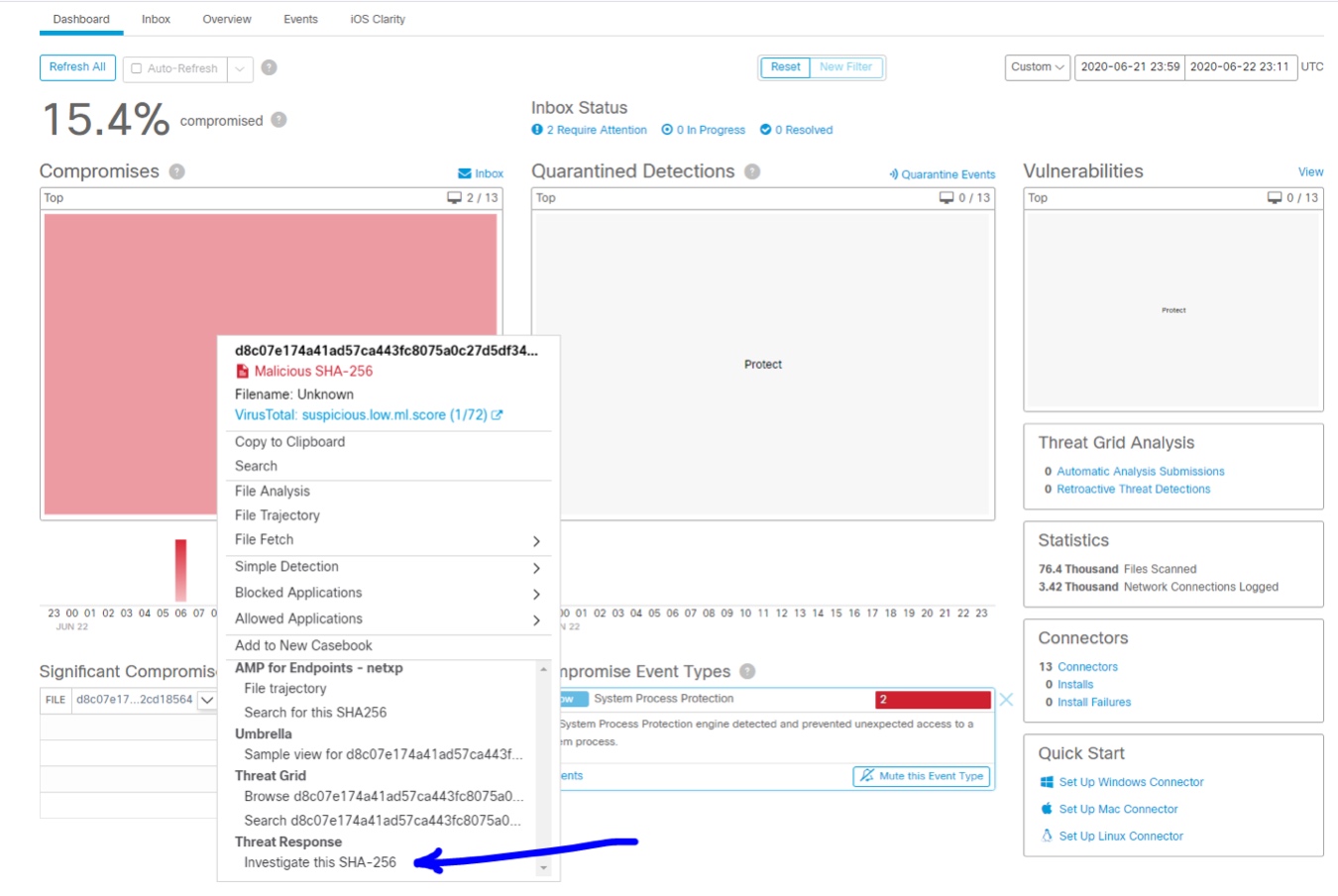
Tutaj pragniemy przywołać system Cisto Threat Reponse. System ten jest darmowy w wypadku wykorzystywania innych narządzi bezpieczeństwa firmy Cisco takich jak np. Cisco Umbrella lub Cisco AMP.
W ramach narzędzia Cisco Threat Response możemy łatwo wizualizować propagację zagrożenia w sieci. Wywołać narzędzie Cisco Threat Reponse można albo bezpośrednio z narzędzi Cisco AMP Cisco Ubrella. Pokazano to na rysunku poniżej, gdzie zlecamy śledzenie zagrożenia zaobserwowanego na jednym z urządzeń.
Narzędzie Threat Reponse pozwala na analizę historyczną wystąpienia problemu w ramach infrastruktury, oraz analizę w postaci grafu propagacji zagrożeń.
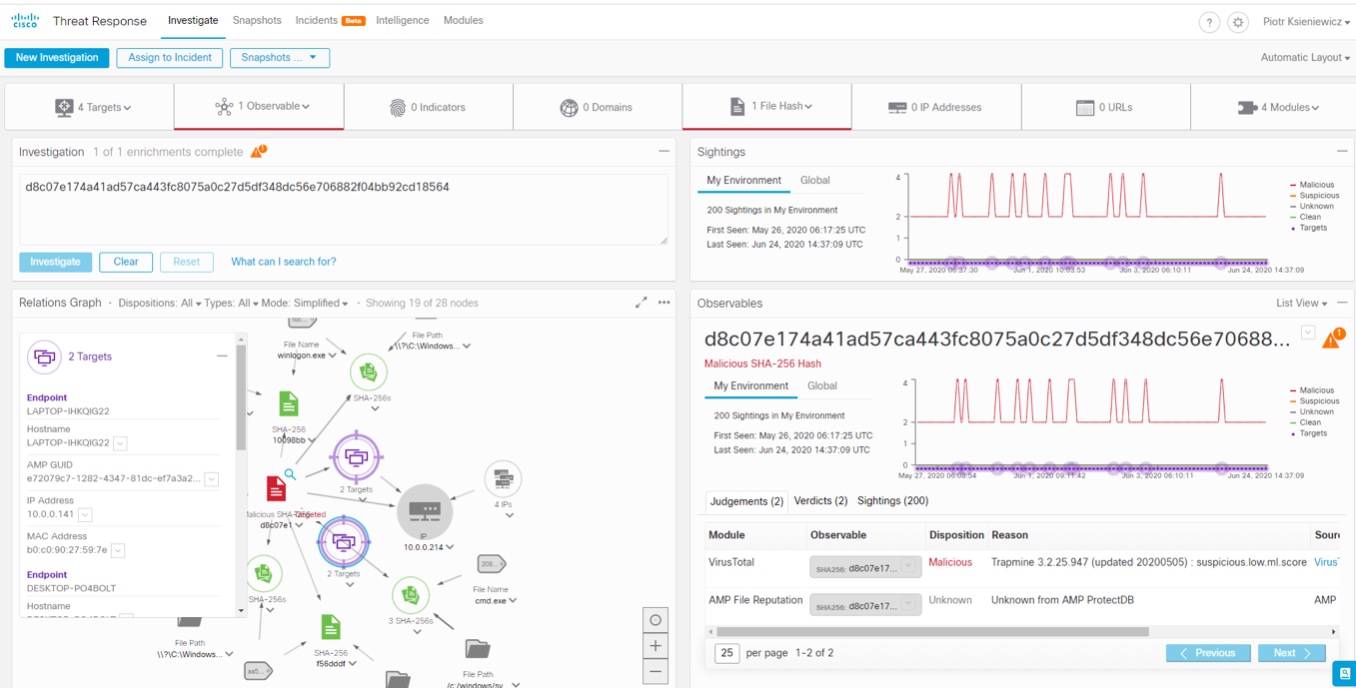
Wizualne przedstawienie informacji o wykrytych zagrożeniach pozwala na ich precyzyjną eliminację.
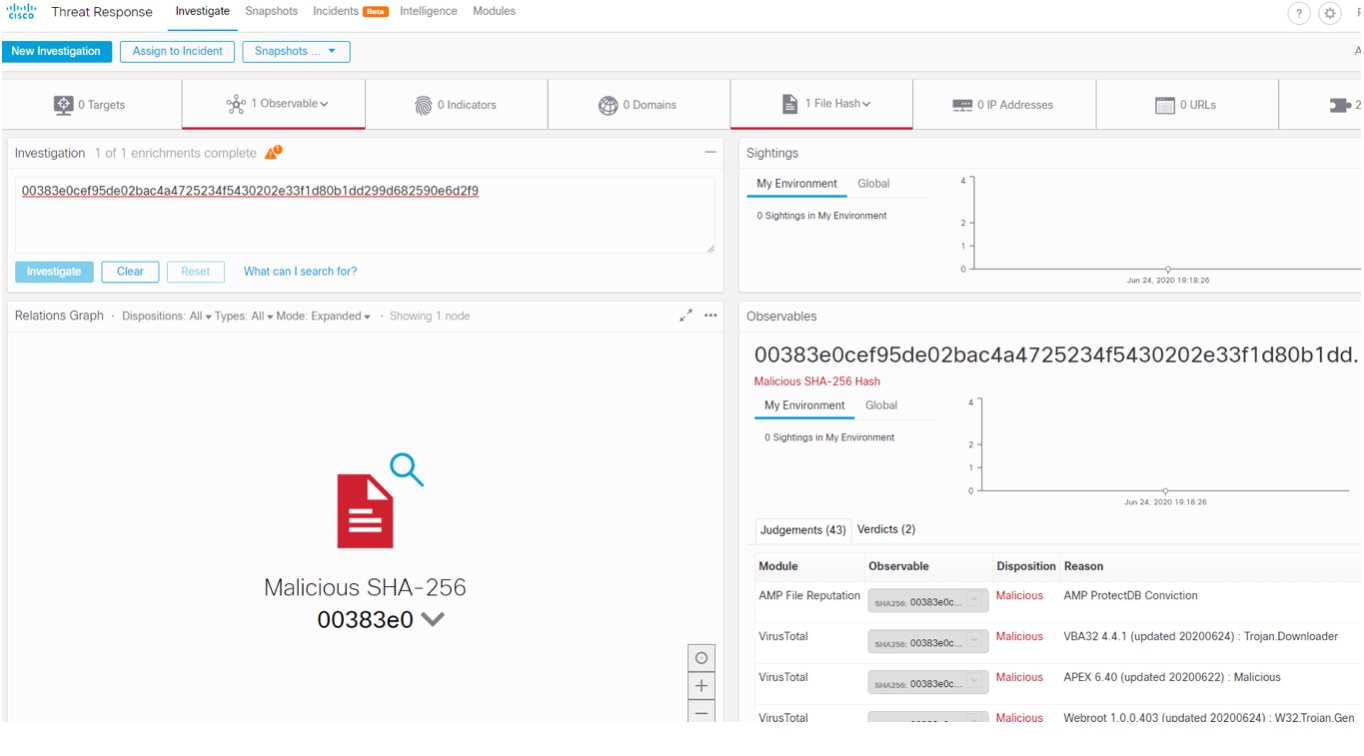
Jednocześnie warto zauważyć, że Threat Response pozwala odpowiadać na pytanie o to czy dane zagrożenie kiedykolwiek było widziane w sieci. Threat Response możemy odpytywać o nazwy plików z zagrożeniami (pozyskane z baz Threat intelligence), nazwy domen, z których zagrożenie mogło pochodzić, podpisów SHA konkretnego pliku.
Na zrzucie ekranu poniżej widać przykład zagrożenia wyszukanego po podpisie SHA, które nie było obserwowane w monitorowanej sieci.
Skanery podatności
W stałym monitorowaniu bezpieczeństwa niezbędna jest także częsta analiza podatności występujących w naszym środowisku. Narzędzi oferujących takie możliwości jest całkiem sporo. Są dostępne narzędzia ogólnego przeznaczenia, jak i takie, które służą do wykrywania podatności tylko w konkretnych systemach (np. aplikacje webowe, systemy CMS). Pośród narzędzi ogólnego przeznaczenia można wymienić systemy:
Nessus
OpenVAS
Oba narzędzia aktywnie skanują zdefiniowane klasy adresowe w poszukiwaniu otwartych portów, dla otwartych portów podejmowana jest próba odkrycia nazwy i typu usługi wykorzystującej dany port. Dla usług i ich wersji przeglądana jest baza zagrożeń CVE, np. taka jak dostępna tutaj.
Określane są potencjalnie występujące luki bezpieczeństwa i umieszczane w stosownym raporcie. Co więcej, automatyczne narzędzie skanowania podatności może posunąć się dalej nawet do wykonania automatycznych prostych ataków na uruchomione usługi takich jak: ataki brute-force, słownikowe na hasła, ataki na aplikacje webowe: XSS, SQL injection itp. Wszystkie te informacje sa podawane w postaci raportu. Poniżej fragment raportu generowanego przez OpenVAS:
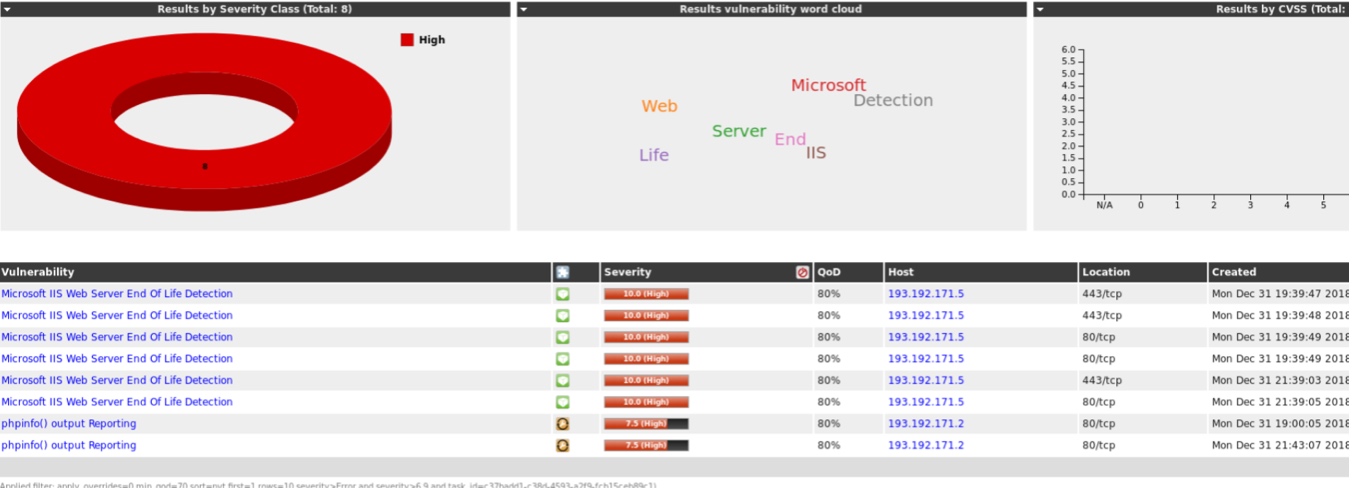
Informacje pozyskane z raportów w oczywisty sposób powinny posłużyć do uszczelniania systemu. Jako że testy wykonywane są automatycznie, to można zaplanować ich cykliczne wykonywanie. Częstotliwość tego procesu zależeć powinna od zmienności infrastruktury.
Podsumowanie
Cyberbezpieczeństwo można monitorować, nawet relatywnie niewielkim kosztem w zakresie zakupów stosownego oprogramowania. Można korzystając z narzędzi bezpłatnych lub kosztujących niewiele stworzyć system, który na bieżąco będzie weryfikował nasze cyberbezpieczeństwo.
Jednocześnie jednak należy podkreślić, że budowa systemu monitoringu i ochrony wymaga dogłębnej wiedzy oraz analizy konkretnego środowiska informatycznego i biznesowego, oraz dopasowania rozwiązań do konkretnych potrzeb. Chętnie podejmiemy się takiego zadania – zapraszamy do kontaktu 😊
Dodatkowo, dla osób zainteresowanych pogłębieniem wiedzy, którą przedstawiłem w tym artykule, polecam też nasze szkolenie na którym w dokładny sposób opisujemy przedstawione w artykule rozwiązania.


 Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów!
Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów! Każdy powinien zobaczyć te webinary! Praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy oraz darmowy webinar.
Każdy powinien zobaczyć te webinary! Praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy oraz darmowy webinar.
Skrótem od Security Operations Center jest SOC, a nie SoC. Ten drugi skrót oznacza System on a Chip.
A gwoli wyjaśnienia to małe litery w skrótach stawia się w zastępstwie przyimków, zaimków itp.
Zwróciłbym również uwagę na skandaliczną pogardę dla interpunkcji… To właśnie polski internet – praktycznie żadnych merytorycznych głosów, tylko sami przyp*****lacze.
Zgadza się. Autor napisał dobrze, nawalił recenzent, czyli ja:)
Nie biczuj się, artykuł jest ok!
Jak na art sponsorowany to nawet spoko zawartość.