27/2/2018

Wracamy z naszym podcastem. Tym razem Marcin samodzielnie przeprowadza Was przez techniki (de)anonimizacji głosu. Odcinek krótki, ale treściwy! Niebawem kolejne :)

Posłuchaj tego odcinka
Listen to “NP #006 – ten o anonimizacji wywiadów” on Spreaker.
Zasubskrybuj nas, aby nie przegapić nowych odcinków
Najwygodniej jest nas zasubskrybować poprzez dowolną aplikację do słuchania podcastów. Po prostu wyszukaj tam “niebezpiecznik” lub “na podsłuchu”, w swojej ulubionej aplikacji do podcastów, a Twoim oczom ukaże się:

Kliknięcie w “Subscribe” sprawi, że będziesz automatycznie informowani o kolejnych odcinkach. Możesz też kliknąć w poniższy przycisk, aby zapisać się na podcast przez iTunes:
Aktualizacja 1.03.2018 13:01
Nasz Czytelnik – Jacek SQ5BPF – w mailu do nas słusznie zauważył, że nagranie obniżone i następnie podwyższone jest ostatecznie… jakby trochę za nisko. To nawet słychać na pierwszy “rzut ucha”, ale Jacek mógł to również udowodnić.
Lepiej podwyższone nagranie, na którym naprawdę da się rozpoznać głos, dostępne jest tutaj.
Czy w takim razie chcieliśmy was oszukać publikując to nagranie? Wcale nie. Po prostu jeśli obniżycie głos o wartość X i następnie podwyższycie również o wartość X (wyrażoną procentowo), często uzyskacie nagranie nieco obniżone. Czyli wiedza o tym, o ile ktoś obniżył nagranie, też może być myląca.
Jacek przeanalizował on spektrogram, czyli wykres pokazujący zakres zarejestrowanych częstotliwości w czasie. Na wykresie poniżej widać moment obniżenia nagrania o oktawę. Możecie zaobserwować co się stało z pasmem szumów w okolicach 12 kHz. One zostały obniżone razem z głosem i nadal są widoczne… tylko niżej, w okolicach 6 kHz.

Przy obniżeniu o kwintę to wyglądało nieco inaczej.
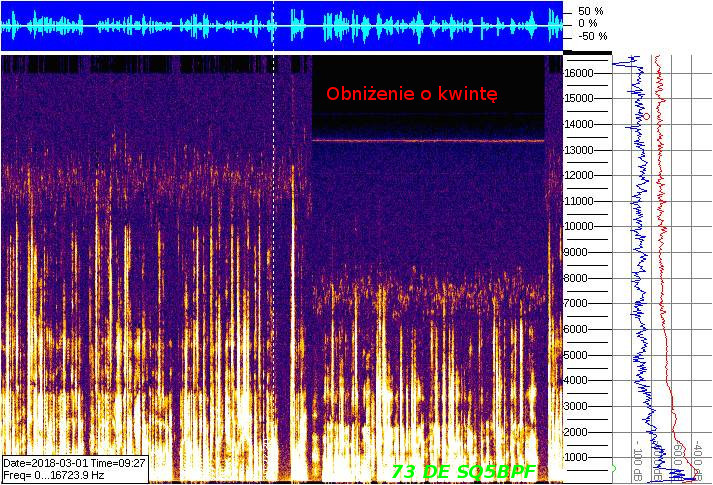
Nagranie obniżone i kwitnę i następnie podwyższone wyglądało na wykresie tak.
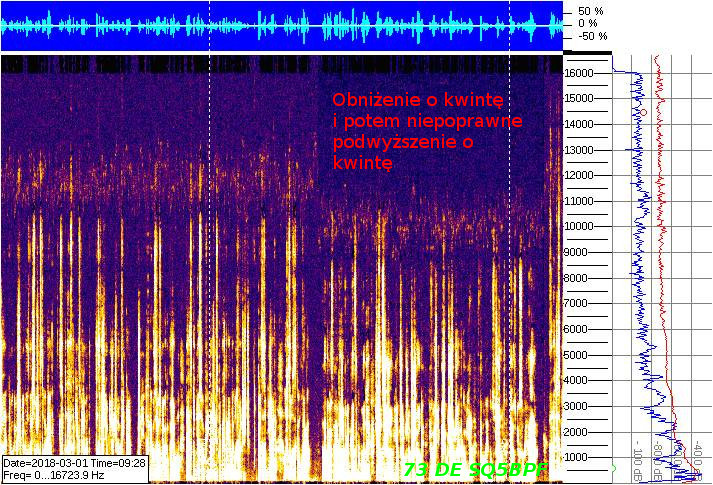
Wyraźnie widać, że pasmo szumów nie jest na miejscu. Przebiega niżej niż powinno.
Niektórzy z was może powiedzą, że Jacek miał łatwo bo mógł porównać niezmienione fragmenty nagrania z tymi zmienionymi. Owszem, ale przecież punkty odniesienia mogą być różne. Gdybyście np. udzielali wypowiedzi na mieście i w tle nagra się syrena pociągu, będzie to dobry punkt odniesienia dla kogoś, kto chciałby później was zdeanonimizować. W programach telewizyjnych, gdzie zmieniane są głosy, często dochodzi do nagrywania w środowisku pełnym dodatkowych dźwięków.
Oprogramowanie użyte przez Jacka to m.in. Spectrum Lab. Jeśli będziecie chcieli się bawić w podobne analizy na popularnych programach (np. Audacity) wybierzcie “Ustawienia spektrogramu” i przestawcie maksymalną częstotliwość (np. na 15000). Domyślne ustawienia nie pozwolą od razu zobaczyć tych szumów, które dla Jacka były wskazówką.
Szczerze mówiąc spodziewaliśmy się, że ktoś to w końcu zauważy to lekkie obniżenie na spektrogramie. Przy okazji – jeśli chcecie się dowiedzieć czegoś więcej o analizie spektrograficznej w rozpoznawaniu głosu to zajrzyjcie do artykułu Jerzego Sawickiego na ten temat.
Wszystkie odcinki w jednym miejscu
“Na Podsłuchu” ma także swoją stałą stronę na Niebezpieczniku:
Tam znajdziecie player pozwalający odsłuchać wszystkie odcinki oraz listę linków do postów z dodatkowymi informacjami dla każdego z poprzednich odcinków (m.in. ze spisem omawianych artykułów oraz narzędzi). Można nas też słuchać na YouTube.
Do następnego podsłuchania!


 Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów!
Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów! Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Długo nie było, ale nareszcie jest odsłucham przy najbliższej okazji
Panowie robicie dobrą robotę tym podcatsem. Szkoda, że tak rzadko :)
Super :) proszę o więcej takich ciekawostek :)
Program do rozpoznawania mowy -> plik tekstowy -> syntezator mowy. Skutecznie, ale mogą wtedy wyjść śmieszne kwiatki.
Ale żadna anonimizacja dźwięku nie pomoże, jeśli można kogoś namierzyć po treści wypowiedzi (patrz: Ted Kaczyński – Unabomber).
Fajnie by było was posłuchać na Spotify ;) Im więcej platform tym więcej słuchaczy zapewne.
Niestety, Spotify nie wpuszcza polskich podcastów ;(
A gdyby po prostu stosować oprgramowanie typu text to speech?
Takie zniekształcania powodują, ze nie idzie zrozumiec co jest mowione. Przeciez mozna zrobic tak, ze lektor czyta tekst przekazu. Jest komunikat glos autora ukryty, czyta lektor itp. Wtedy nikt nie rozpozna. Albo uzywac napisów i Ivony :)
>“Na Podsłuchu” ma także swoją stałą stronę na Niebezpieczniku:
Ponawiam propozycję, aby dodać linki do stałych stron cyklicznych materiałów (wideoporadnik, podcast, memdump) do elementów nawigacyjnych strony (np. do poziomego menu, lub gdzieś z boku – miejsce na pewno się znajdzie). Możnaby również wyświelać obok nazwy cyklu jakąś ikonkę typu “new!” sygnalizującą, że właśnie/niedawno ukazał sie nowy odcinek.
Doskonały pomysł. Zrobimy!
Jak to nie wypuszcza?
https://open.spotify.com/search/results/swps
Znajdziesz jeszcze kogoś?
Uwaga ludzie! Informacja uzupełniająca!
Jeden z Czytelników słusznie zauważył, że nagranie podniesione o kwintę po uprzednim obniżeniu o kwintę jest jakby trochę za nisko. Ma rację, ponieważ przy korzystaniu z popularnego softu (choćby takiego w rodzaju audacity) obniżenie o daną wartość i następnie podniesienie o tę samą wartość sprawi, że będziemy ciut za nisko. Bardziej skutecznej deanonimizacji można dokonać analizując np. szumy mikrofonu.
Niebawem dorzucimy aktualizację, która pokazuje jak można to zrobić lepiej.
To oczywiste, że dźwięk obniżony o 30% a następnie podwyższony o 30% będzie niższy od oryginału. To nie kwestia programu, tylko matematyki. 30% z większej wartości to więcej niż 30% z mniejszej wartości. Przykład:
Mamy ton 1000Hz, obniżamy go o 50%= uzyskujemy 500Hz. Jeśli te 500Hz podwyzszymy o 50% uzyskamy… 750Hz (bo 50%*500=250).