17/8/2020

Jeżeli zajmujesz się tworzeniem albo testowaniem aplikacji webowych, na pewno nie raz zastanawiałeś się jakie jeszcze zabezpieczenia wprowadzić i jakie testy wykonać, aby w przyszłości uniknąć artykułu na stronie głównej Niebezpiecznika opisującego właśnie ujawnione błędy i wycieki z Twojej aplikacji. Ale co, jeśli pomimo Twoich usilnych prób, do incydentu jednak dojdzie?
Loguj i monitoruj
Tutaj z pomocą przychodzi logowanie i monitorowanie zdarzeń. Dzięki nim możesz nie tylko przeprowadzić analizę incydentu (jak do tego doszło?), określić skalę ewentualnego wycieku (co i skąd wyciekło, do czego dostęp miał atakujący?), ale niekiedy także powstrzymać atakującego zanim przełamie zabezpieczenia, o ile czytasz logi lub raczej odpowiednio skonfigurowałeś narzędzia, które na bieżąco je interpretują.
Błędy związane z logowaniem i monitorowaniem zdarzeń występują na tyle często, że organizacja Open Web Application Security Project (OWASP) w 2017 roku wpisała je na listę 10 najczęściej występujących ryzyk dotyczących aplikacji webowych, czyli powszechnie znaną listę OWASP Top 10.
Spróbujmy w tym artykule spojrzeć na temat logów nieco od drugiej strony, czyli nie tylko pod kątem danych, które możemy (i powinniśmy!) logować, ale także tego, co w logach nigdy nie powinno się znaleźć, bo zamiast zwiększyć bezpieczeństwo naszej aplikacji wprowadzi dodatkowe zagrożenie.
Ale nie loguj wszystkiego :)
Większość ataków rozpoczyna się od automatycznego skanowania aplikacji, prób ataków bruteforce itp., a logowanie zdarzeń ma za zadanie umożliwić identyfikację takiego ataku, jego zablokowanie oraz jak najszybsze powiadomienie osób odpowiedzialnych za atakowany system.
Dla zapewnienia najwyższego poziomu bezpieczeństwa kuszące wydaje się logowanie możliwie największej ilości danych. Nie jest to jednak dobre podejście. Zapisując zbyt wiele możemy narazić nasz system na dodatkowe zagrożenia. Przykładowo:
rejestrując prywatne lub poufne dane możemy spowodować, że nasz system będzie niezgodny z obowiązującymi regulacjami dotyczącymi ochrony danych osobowych, a my z naszych logów stworzymy kolejne miejsce przechowywania danych, których wyciek może mieć dla nas bardzo poważne konsekwencje.
Przykład #1 – Logowanie identyfikatora sesji
Na Stack Overflow można spotkać porady dotyczące logowania identyfikatora sesji w celu powiązania zdarzenia z konkretnym użytkownikiem. Jest to jednak nienajlepszy pomysł, a jego realizację możemy od razu uznać za problem, który może doprowadzić do ataku typu Session Hijacking. Podatność ta polega na przejęciu identyfikatora sesji, a następnie użyciu go przy własnym połączeniu, co umożliwia działanie w sesji użytkownika i dostęp do jego konta bez konieczności zalogowania. Co prawda nie znamy hasła użytkownika, ale nie jest nam ono potrzebne bo mamy identyfikator aktywnej sesji i z jego pomocą możemy się podszyć pod użytkownika.
Taki atak może zostać wykonany przez każdą osobę mającą dostęp do logów, zarówno przez atakującego z wewnątrz organizacji np. administratora (choć on często użytkownikowi może zaszkodzić na wiele innych sposobów), ale przede wszystkim przez zewnętrznego atakującego, któremu udało się uzyskać dostęp do logów czy to za pomocą innej podatności czy poprzez uzyskanie dostępu do publicznego katalogu, w którym składowano logi, innego systemu na który je wysyłano — w tym także np. skrzynek e-mailowych developerów.
Uzyskanie dostępu do logów jest często łatwiejsze niż przełamanie zabezpieczeń aplikacji. Zdarza się, że logi są dostępne w aplikacjach do gromadzenia i wizualizacji logów np. Elasticsearch, Kibana bez konieczności zalogowania, a ze względu na nieprawidłowości w separacji podsieci dostęp sieciowy do nich ma (zbyt) wiele osób z danej organizacji, lub w skrajnych przypadkach, z powodu błędów konfiguracyjnych, są one wystawione do Internetu. Tutaj dobrym przykładem jest chociażby opisywany niedawno atak MEOW.
Nigdy nie zapisuj identyfikatora sesji w logach, zwłaszcza systemów produkcyjnych! Jeżeli niezbędne jest powiązanie zdarzeń z konkretną sesją np. w celu łatwiejszego debugowania dopuszczalną opcją jest zapisanie np. haszy identyfikatorów sesji.
Rzuć okiem na ASVS
O tym, że nie można zapisywać identyfikatora sesji w logach mówią także wytyczne OWASP ASVS, czyli podzielonego na obszary (np. architektura, walidacja wejścia, uwierzytelnienie, obsługa błędów) standardu dotyczącego zabezpieczania i testowania aplikacji webowych. W aktualnej wersji 4.0.1 logowaniu zdarzeń poświęcona jest sekcja V7: Error Handling and Logging Verification Requirements. Najbardziej interesująca w omawianym tutaj kontekście jest sekcja 7.1 i punkt 7.1.1. Poniżej fragment dokumentu OWASP ASVS:

Jeżeli jesteś analitykiem, deweloperem albo testerem i nie miałeś jeszcze okazji korzystać z dokumentu OWASP ASVS zachęcam do zapoznania się z zawartymi w nim rekomendacjami i weryfikacjami. Dokument może okazać się przydatny zarówno na etapie opracowywania wymagań pozafunkcjonalnych, jak i później na etapie testów. Szczególnie polecam go testerom, zarówno tym którzy już wykonują testy bezpieczeństwa, jak i tym, którzy chcieliby rozszerzyć zakres wykonywanych przez siebie testów o aspekt bezpieczeństwa. W ASVS znajdziecie liczne “weryfikacje” o które możecie uzupełnić swoje testy aby uwzględniały również scenariusze pozafunkcjonalne w zakresie bezpieczeństwa.
O tym jak zrobić to najsensowniej, a także o wielu innych testach zahaczających o bezpieczeństwo, które z łatwością mogłyby wykonać wewnętrzne działy testerów (QA) dowiesz się na moim szkoleniu, Szkolenie dla QA: bezpieczeństwo w testach oprogramowania, którego najbliższe terminy odbędą się:
ZDALNIE: 26-27 sierpnia 2024r. — UWAGA: zostały tylko 2 wolne miejsca
Ostatnio ktoś zarejestrował się 25 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 26 lipca)
2499 PLN netto (od 27 lipca)
Warszawa: 16-17 września 2024r. — UWAGA: zostały tylko 4 wolne miejsca
Ostatnio ktoś zarejestrował się 25 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 26 lipca)
2499 PLN netto (od 27 lipca)
Kraków: 14-15 października 2024r. — zostało 7 wolnych miejsc
Ostatnio ktoś zarejestrował się 12 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 2 sierpnia)
2499 PLN netto (od 3 sierpnia)
Przykład #2 – Logowanie danych osobowych
O tym aby nie logować danych osobowych mówi punkt 7.1.2 ASVS oraz inne dobre praktyki wytwarzania oprogramowania. Danymi których nie powinniśmy logować (bez wyraźnej potrzeby i zgody) będzie np. PESEL, adres IP, adres e-mail itp. Spośród powyższych w logach bardzo często zapisywany jest adres IP. Czy to duży problem?
Adres IP może być traktowany jako dana osobowa (takie jego kwalifikowanie będzie zależeć od pewnych dodatkowych kwestii np. tego z jakimi innymi danymi jest przetwarzany albo jak długo jest przypisany do urządzenia). Załóżmy, że w Twojej organizacji prawnicy są zdania, że adresy IP to dane osobowe, więc użytkownicy powinni zostać poinformowani o ich zapisywaniu, celu ich przetwarzania oraz o tym jak długo takie dane będą przechowywane. W takiej sytuacji logi będą kolejnym miejscem gdzie znajdują się dane osobowe co ma znaczenie m. in. w kontekście zapytań o przetwarzanie, informowania o ewentualnym wycieku, czy otrzymania wniosku o usunięcie. Logi zawierające dane osobowe muszą być przechowywane w sposób bezpieczny, a dostęp do nich musi zostać ograniczony. Zalecane jest przechowywanie logów w formie zaszyfrowanej. Należy pamiętać o poprawnej konfiguracji algorytmów szyfrowania.
Przykład #3 – Tryb DEBUG na produkcji
Innym błędem, który łatwo popełnić, jest ustawienie trybu DEBUG na produkcji, co będzie skutkowało zapisywaniem do logu bardzo dużej ilości informacji lub całych żądań pochodzących od użytkownika. W przypadku żądań logowania lub resetu hasła może to być równoznaczne z zapisaniem hasła w jawnym tekstem (por. Wyciek 600 milionów haseł z Facebooka). To nie koniec problemów. W przypadku innych żądań mogą to być, zależnie od charakteru aplikacji, np. ustawowo chronione dane medyczne, których przypadkowe upublicznienie może nas wpędzić w większe kłopoty niż wpadka z ujawnieniem adresu IP.
Czasem do wartościowych logów aplikacji dostać można się w naprawdę nie wymagający wielkiej wiedzy sposób:
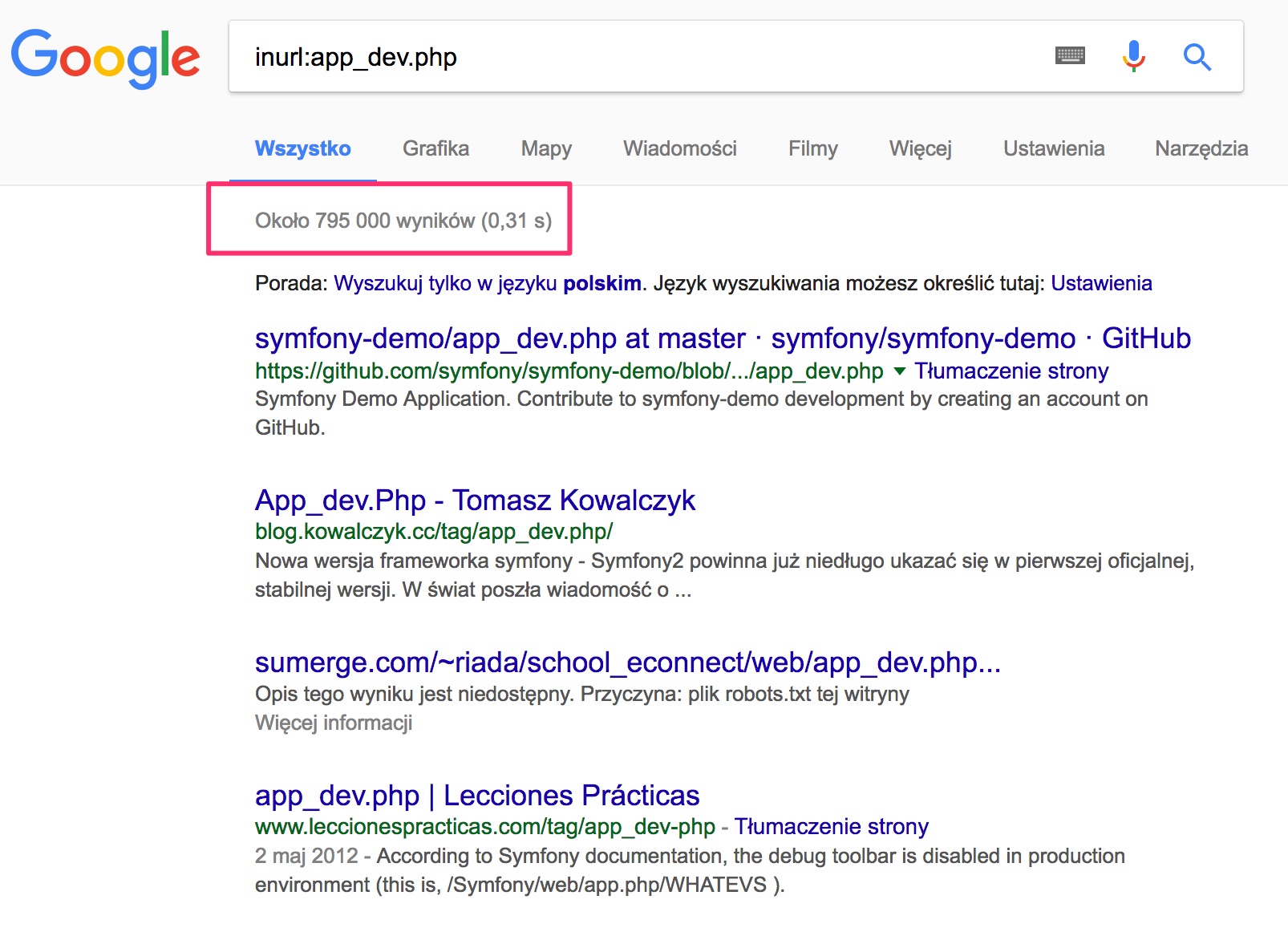
Przykład #4 – Dane wrażliwe w URL
Jeśli w systemie mamy identyfikatory użytkowników takie jak np. PESEL albo adres e-mail, kuszące może się wydawać użycie takiego identyfikatora np. w endpoincie typu: /user/<email>. Przesyłanie danych osobowych w URL i posługiwanie się nimi jako identyfikatorem nie jest jednak dobrym rozwiązaniem, ponieważ powoduje m.in. następujące problemy:
- zapisywanie tych danych w logach aplikacji oraz historii przeglądarki,
- zapisanie w logach i pamięci serwera, z pamięci serwera mogą zostać pobrane także z wykorzystaniem podatności (np. Heartbleed)
- odkładanie w historii proxy, czy też innych logach systemów pośrednich,
- użytkownicy mogą nieświadomie przekazać taki link, przekazując tym samym dane osobowe np. publikując na Facebooku czy OLX,
- dane mogą być dostępne dla rozszerzeń przeglądarki,
- dane mogą zostać przekazane w nagłówku Referer do innych domen do których odnośniki znajdują się na stronie.
To samo dotyczy przekazywania danych wrażliwych w parametrach żądania GET. Dobrym przykładem w tym temacie są serwisy przechowujące dane medyczne. Następnym razem zapisując się na wizytę lekarską, wyszukując leku albo filtrując posiadane recepty polecam zwrócić uwagę na to, czy wszystkie żądania realizowane są metodą POST albo z wykorzystaniem lokalnych identyfikatorów zastępujących np. rzeczywiste identyfikatory lekarzy, jak numer NPWZ, czy imię i nazwisko. W końcu odłożenie w logach informacji o lekarzach lub lekach mówi wiele o ewentualnych problemach zdrowotnych.
Pozostając w tematyce medycznej wspomnę jeszcze o wpadce amerykańskiego serwisu HealthCare.gov, który przekazywał dane o stanie zdrowia użytkowników do zewnętrznych systemów monitorujących ich aktywność. Dane były przekazywane poprzez nagłówek Referer, a wszystko przez ich wcześniejsze przekazywanie w URL.
Jak testerzy mogą wykrywać takie błędy?
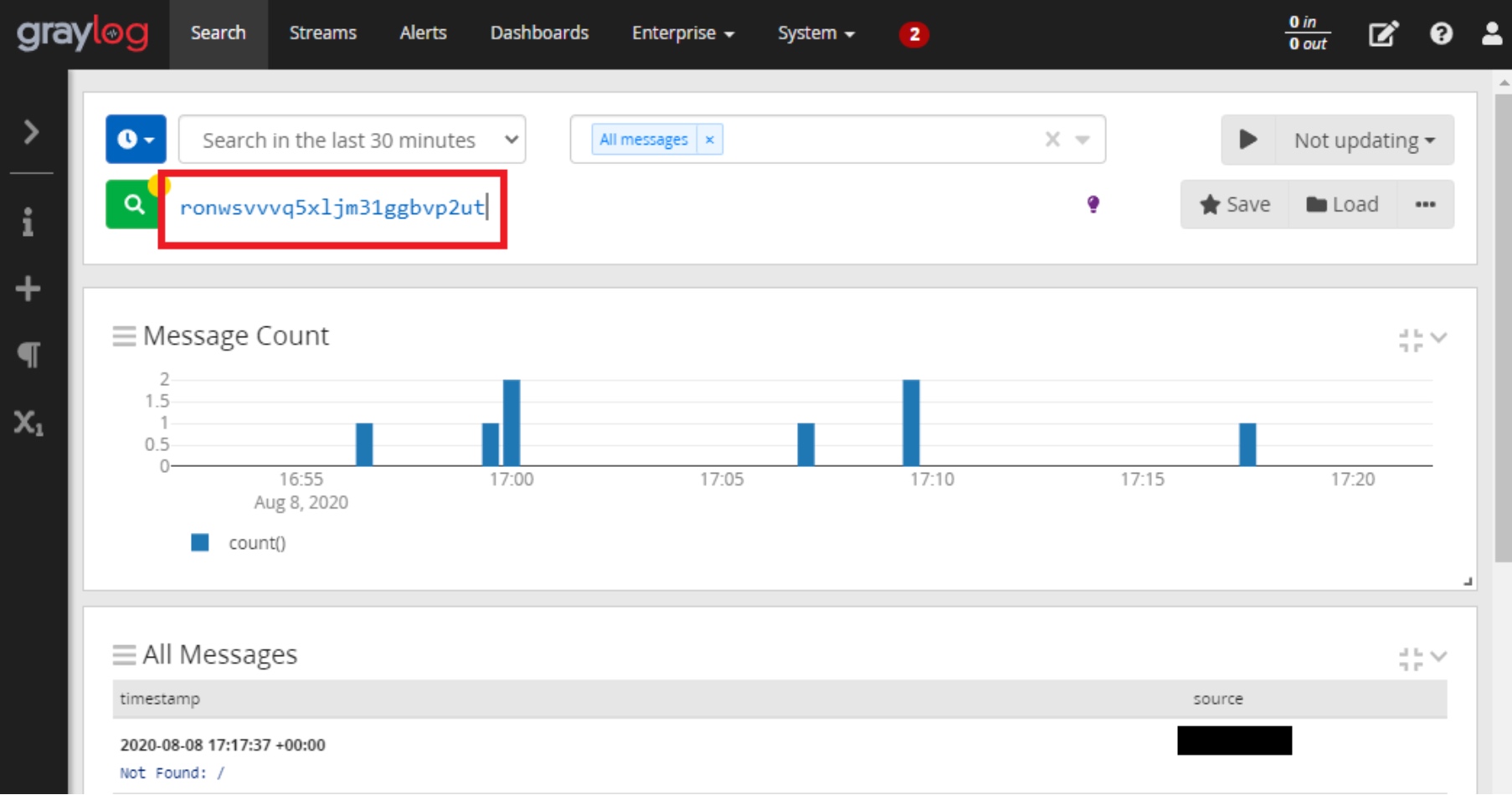
Jeżeli jesteś testerem to zachęcam do regularnego sprawdzania, czy błędy związane z logowaniem zdarzeń nie dotyczą również Twojej aplikacji. Najprostsze testy mogą polegać na zalogowaniu do aplikacji i wykonaniu podstawowych operacji, a następnie przeszukaniu logów pod kątem danych które wprowadziliśmy, czyli np. po wykonaniu testu przeszukujemy logi po identyfikatorze sesji. Jeśli korzystacie z systemów do gromadzenia logów czasami wystarczy jedynie przeszukanie z wykorzystaniem interfejsu webowego np. Kibany albo Grayloga. Warto też przeszukać logi pod katem prostych przekształceń naszego ciągu (po różnym sformatowaniu np. numerów i po przetworzeniu popularnymi funkcjami, nie tylko skrótów).
Jeśli masz przygotowane testy automatyczne to zachęcam do rozszerzenia ich o weryfikację logów. Przykładowo, jeśli formularz w aplikacji zawiera pola, w które użytkownik wpisuje swój adres i numer PESEL, to nic nie stoi na przeszkodzie aby po teście automatycznym (Selenium) przeszukać logi pod kątem obecności tych danych. Jako uzupełnienie powyższych testów warto również w przeglądarce zobaczyć, czy dane wrażliwe nie są przekazywane w URL. Tutaj wystarczy uruchomić narzędzia deweloperskie przeglądarki i w zakładce Network podejrzeć z wykorzystaniem jakiej metody przesyłane są żądania. Jeśli dane przekazywane są w URL oczywiście zobaczymy je również na pasku adresu w przeglądarce.
Do podejrzenia struktury i historii żądań można również wykorzystać narzędzia typu lokalnego proxy dedykowane dla testów bezpieczeństwa np. Burp Suite, czy OWASP ZAP, które omawiam na naszym szkoleniu poświęconym dodawaniu aspektów bezpieczeństwa do pracy testerów QA.
Jakie dane powinniśmy logować?
Skoro planujecie już weryfikację logów pod kątem danych, których nie powinny zawierać to na koniec warto krótko wymienić jakie informacje mogą i jakie powinny się w logach znaleźć. Zgodnie z OWASP Cheat Sheet oraz OWASP Top 10 Proactive Controls 2018, czyli zestawem zaleceń dla programistów, dotyczących tworzenia bezpiecznego oprogramowania, zdarzeniami które należy rejestrować aby móc zidentyfikować ewentualne niepożądane działania użytkowników są zdarzenia takie jak:
- Błędy walidacji danych wejściowych:
- przesłanie danych spoza oczekiwanego zakresu (np. wartości spoza dozwolonego zakresu liczbowego, ciąg znaków w polu liczbowym),
- przesłanie danych niepoprawnie kodowanych,
- niepoprawne nazwy parametrów.
- Błędy walidacji danych wyjściowych (np. niepoprawne kodowanie danych, błędy bazy danych takie jak database record set mismatch).
- Przesłanie zmienionych danych dla których użytkownik nie ma możliwości modyfikacji (np. lista wyboru, pole wyboru lub wartości z pól ukrytych dla użytkownika).
- Uwierzytelnianie, zarówno zakończone sukcesem jak i błędem.
- Żądania naruszające reguły kontroli dostępu po stronie serwera (wszystkie błędy kontroli dostępu).
- Błędy zarządzania sesją (np. modyfikacja wartości identyfikatora sesji).
- Błędy aplikacji i zdarzenia systemowe, np. błędy typu syntax and runtime errors, problemy z połączeniem, wydajnością, komunikaty o błędach usług zewnętrznych, błędy systemu plików, wykrycie wirusów w przesyłanych do aplikacji plikach, zmiany konfiguracyjne.
- Uruchamianie i wyłączanie aplikacji i powiązanych systemów oraz systemu logowania (uruchamianie, zatrzymywanie lub wstrzymywanie).
- Wszelkie wykorzystanie funkcji o wyższym ryzyku bezpieczeństwa, np. utworzenie połączenia sieciowego, dodawanie lub usuwanie użytkowników, zmiany uprawnień, generowanie lub usuwanie tokenów użytkowników, korzystanie z uprawnień administracyjnych systemów, dostęp z kont administratorów aplikacji, wszystkie działania użytkowników z uprawnieniami administracyjnymi, dostęp do danych wrażliwych np. danych karty płatniczej, zapisanie zgody na wykorzystanie danych osobowych lub otrzymywanie komunikatów marketingowych, tworzenie i usuwanie obiektów na poziomie systemu, importowanie i eksportowanie danych itp.
Podsumowanie
Weryfikacja zawartości logów jest jednym z podstawowych testów bezpieczeństwa, które może wykonać każdy członek zespołu (tester i nie tylko). O weryfikację logów można rozszerzyć testy manualne jak i dodać je do testów automatycznych.
Więcej o bezpieczeństwie w testach oprogramowania oraz o podstawowych testach bezpieczeństwa, które może wykonać każdy tester z wykorzystaniem znanych już narzędzi i frameworków opowiem podczas szkolenia Szkolenie dla QA: bezpieczeństwo w testach oprogramowania, którego najbliższe terminy odbędą się:
ZDALNIE: 26-27 sierpnia 2024r. — UWAGA: zostały tylko 2 wolne miejsca
Ostatnio ktoś zarejestrował się 25 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 26 lipca)
2499 PLN netto (od 27 lipca)
Warszawa: 16-17 września 2024r. — UWAGA: zostały tylko 4 wolne miejsca
Ostatnio ktoś zarejestrował się 25 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 26 lipca)
2499 PLN netto (od 27 lipca)
Kraków: 14-15 października 2024r. — zostało 7 wolnych miejsc
Ostatnio ktoś zarejestrował się 12 lipca 2024r. → zarejestruj się na to szkolenie
-
2299 PLN netto (do 2 sierpnia)
2499 PLN netto (od 3 sierpnia)


 Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów!
Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów! Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Witamy Klarę wśród autorów! Bardzo przystępnie opisane, dzięki za info o prywatnościowych dokumentach OWASP, nie znałem!
Może w kolejnym artykule jakiś tutorial korzystania ze wspomnianych w tym tekscie narzędzi?
O tych narzedziach nigdy nie slyszalem, zerkne z ciekawosci, natomiast sklanialbym sie bardziej w strone analizy ruchu sieciowego bazujac na podstawowych i czesto wbudowanych narzedziach (najczesciej spotykanych w systemach linux/unix) i nauki pisania filtrow do analizy i filtrow sieciowych, co bardziej uelastycznia i uniezaleznia pracę prawdziwego administratora. Ludzie z niebezpiecznika wydaje się jakby skrzętnie chowali tę wiedzę, lub właśnie tym handlują. Z ciekawosci moze kiedys sie zapiszę :p
Tego wlasnie nie rozumieja nietechniczni byznesmeni.
Stworzenie system zwiazanego z bezpieczenstwem jest zawsze wielokrotnie drozsze nawet niz systemy krytyczne, poniewaz nie dosc ze musi byc pieronsko reliable to bierzaca diagnostyka kwalifikuje sie jako failure (co nie ma miejsca w systemach krytycznych niezwiazanych z bezpieczenstwem – reaktor nie musi ukrywac przed operatora ze sie przegrzewa bo woda zbyt wolno cyrkuluje, w obawie ze uslyszy to celujacy na slepo sabotazysta ktory wywnioskuje tego w ktorym kierynku zkoncentrowac swoje wysilki…).
Ps. I tak, bede wtrącal angielskie slowka. Jak sie nie podoba to mozecie sobie pobrusić na żarnach…
Obce słowa czy brak plogonków to nie problem, ale o deklinację i ortografię to już byś mógł zadbać w wolnej chwili. ;)
Taka ciekawostka :) ostatnio spotkałem się z API, które przesyła dane poprzez GET urlem bez szyfrowania (pesel/nip etc pod generowanie faktur) – co ciekawe to oprogramowanie ERP za gruby hajs – ja osobiście nie polecam
Jak rozumiem, logowanie błędów w zapytaniach SQL do bazy danych też jest błędne i lepiej tego nie robić? W błędnych zapytaniach typu INSERT lub UPDATE moga znajdować się każde akurat zmieniane dane, w tym te, których w logach być nie powinno. Albo logować tylko „surową” formę zapytania SQL przed przetworzeniem placeholderów (zakładając, że korzystamy z jakiejś sensownej warstwy abstrakcji do ochrony przed SQL injection)?
@Niebezpiecznik – podaję za nagłowkiem z poprzedniej próby wysłania tego posta :
“Twój komentarz pojawi się niebawem (po akceptacji przez moderatora)
markooff 2020.09.02 10:22 | # | Reply”
@Tomasz Gąsior
Jak najbardziej :) Ale nawet w przypadku użycia (po prostu: użycia) takiej warstwy abstrakcji (jak np. w czystym php – PDO wraz z prepared statements i przy obsłudze wyjątków w konstrukcji try-catch ) jeśli się nie skorzysta z jakichś gotowców z dedykowanymi klasami obsługi/logowania – to trzeba pamiętać że niektóre z placeholderów SĄ i POWINNY znaleźć się w logach po rozwinięciu np: te precyzujące warunki w zapytaniu
(po WHERE … ) choć znów czasem może się okazać że jednak nie wszystkie.
Podobnie – dedykowane metody (statyczne) odczytywania błędów np. PDOStatement::errorinfo() – są bardzo dokładne i rozmowne :) ale się zgodzicie że bez dalszego filtrowania – zrobiła by w logach więcej złego niż dobrego. Na szczęście pisanie własnych klas obsługi logowania błędów (czy też obsługi wyjątków) to w zasadzie chyba norma.
@autorka (Klara)
naprawdę świetny materiał. niestety zbyt późno chyba go znalazłem :) bo dyskusja już jakoś trochę zamarła – tym niemniej z chęcią skorzystam ( i juz skorzystałem :) ) z opracowania OWASPowego – i muszę napisać – ze jestem pod wrażeniem .
Może by tak częściej się zaczęły pojawiać materiały tego (z tej materii) typu na łamach niebezpiecznika – na pewno zyskamy na tym wszyscy .
Pozdrawiam
@Tomasz Gąsior
Jak najbardziej :) Ale nawet w przypadku użycia (po prostu: użycia) takiej warstwy abstrakcji (jak np. w czystym php – PDO wraz z prepared statements i przy obsłudze wyjątków w konstrukcji try-catch ) jeśli się nie skorzysta z jakichś gotowców z dedykowanymi klasami obsługi/logowania – to trzeba pamiętać że niektóre z placeholderów SĄ i POWINNY znaleźć się w logach po rozwinięciu np: te precyzujące warunki w zapytaniu
(po WHERE … ) choć znów czasem może się okazać że jednak nie wszystkie.
Podobnie – dedykowane metody (statyczne) odczytywania błędów np. PDOStatement::errorinfo() – są bardzo dokładne i rozmowne :) ale się zgodzicie że bez dalszego filtrowania – zrobiła by w logach więcej złego niż dobrego. Na szczęście pisanie własnych klas obsługi logowania błędów (czy też obsługi wyjątków) to w zasadzie chyba norma.
@autorka (Klara)
naprawdę świetny materiał. niestety zbyt późno chyba go znalazłem :) bo dyskusja już jakoś trochę zamarła – tym niemniej z chęcią skorzystam ( i juz skorzystałem :) ) z opracowania OWASPowego – i muszę napisać – ze jestem pod wrażeniem .
Może by tak częściej się zaczęły pojawiać materiały tego (z tej materii) typu na łamach niebezpiecznika – na pewno zyskamy na tym wszyscy .
Pozdrawiam