12/4/2014

Tak, to kolejny, już 4 z rzędu artykuł o Heartbleedzie (na pocieszenie, na jego końcu obiecuję wstawić skoczną piosenkę). Pisaliśmy już co prawda zarówno o tym jak wielkie żniwo zebrał atak Heartbleed, na czym polega i jak się przed nim ochronić …oraz uczulaliśmy was na to, że Heartbleed pozwala wykradać dane nie tylko z serwerów, ale również z waszych komputerów i telefonów komórkowych. Ale celowo powstrzymywaliśmy się od insynuacji czy błąd był powiązany z służbami NSA — do dziś…

Heartbleed
NSA wiedziało o dziurze wcześniej i miało korzystać z niej “od lat”
Bloomberg właśnie powiedział głośno to, o czym wielu myślało po cichu. W artykule o krzykliwym tytule: “NSA korzystała z Heartbleed od lat“, powołując się na “2 anonimowe osoby powiązane ze sprawą” dziennikarz Bloomberga stawia tezę, że NSA wiedziała o błędzie Heartbleed, ale nie ujawniała tej informacji, bo wykorzystywała błąd do pozyskiwania danych wywiadowczych. Pozwolę sobie skomentować ten artykuł i podzielić się z Wami kilkoma refleksjami w temacie.
Po pierwsze, jeśli rzeczywiście NSA wiedziała o tej dziurze, to nie “od lat“, a od maksymalnie 2 lat, bo wtedy ten błąd po raz pierwszy pojawił się w kodzie OpenSSL.
Po drugie, czy rzeczywiście wiedziała? Na to póki co nie mamy twardych dowodów. Agencja co prawda zaprzecza, ale przecież wielokrotnie przyłapywano ją już na kłamstwach. Ale nawet jeśli przyjąć, że NSA nie znała Heartbleeda wcześniej, to nie oznacza to, że nie wie o innych, podobnie “krytycznych” błędach…
Co ja robiłbym na miejscu NSA?
Zacznę od tego, że wszyscy komentatorzy powinni najpierw zrozumieć, czym jest agencja wywiadowcza — jakie ma cele i jaki ma budżet (czyli możliwości i wpływy). Gdybym zarządzał NSA, miejscem w którym pracuje najwięcej matematyków i ogólnie “wielkich umysłów”, obowiązkowo zbudowałbym dedykowany zespół osób, którego jedynym zadaniem jest wyszukiwanie błędów w najpopularniejszych projektach Open Source. To dość łatwe zadanie, bo wbrew pozorom otwartość kodu wcale nie oznacza automatycznie jego bezpieczeństwa (chociaż publiczny dostęp do historii commitów na pewno pomaga w analizie pofuckupowej). Jak łatwe?
1. Budowa zespołu bughunterów
Kilka lat temu jeden z profesorów na amerykańskiej uczelni wyłożył w 1 semestr swoim studentom “podstawy bezpieczeństwa aplikacji”, a przez 2 semestr kazał im wziąć na warsztat dowolny projekt Open Source i znaleźć w nim błędy bezpieczeństwa. Udało się każdemu zespołowi “świeżych” w temacie bezpieczeństwa studentów (niestety, nie jestem teraz w stanie odnaleźć dokładnego źródła, sprawa ma kilka(naście?) lat, ale ten dokument jest wystarczająco bliski).
Zresztą tezę o łatwości znajdowania błędów bezpieczeństwa potwierdza projekt 2 Polaków, Mateusza “j00ru” Jurczyka i Gynvaela Coldwinda, którzy na tapet wzięli popularną open source’ową bibliotekę kodeków video FFmpeg i znaleźli w niej …1000+ bugów. Dodajmy, że nawet jeśli projekt nie ma dostępnego kodu źródłowego, to błędy bezpieczeństwa też można z łatwością w nim znajdować — i tu znów przytoczę projekt autorstwa j00ru i Gyna, który zaowocował znalezieniem kilkudziesięciu poważnych błędów w Adobe Readerze. Na szczęście obaj pracują dla Google, nie NSA …prawda, chłopaki? ;)
2. Pozyskiwanie kluczowych programistów do współpracy
Drugą moją decyzją, zaraz po stworzeniu dedykowanego zespołu do szukania błędów w kodzie popularnego oprogramowania, byłaby próba zwerbowania do współpracy developerów tworzących kod kluczowego oprogramowania. NSA już to robi. Czasem pewnie oferując pieniądze, innym razem być może szantażując.
Dowodów na naciski służb na programistów jest kilka, np. próba przekupienia programisty Microsoftu pracującego przy projekcie Bitlockera (narzędzie do szyfrowania dysku) do wprowadzenia backdoora. Ponoć służby o to samo prosiły także Linusa. Swego czasu lekkie poruszenie wywołały doniesienia o rzekomym wstrzyknięciu backdoora do implementacji IPSeca na OpenBSD. Historii tego typu pewnie byłoby więcej, gdyby nie prawo, które zabrania osobom z którymi rozmawiały służby na ujawnianie takiego faktu. Na marginesie, podobny paragraf jest w polskim kodeksie karnym… :>
3. Skupowanie 0day’ów z rynku
Mam już swój zespół bughunterów, mam “kupionych” developerów. Ale w bezpieczeństwie informacji, własny, nawet najlepszy zespół bezpieczników nie wystarczy. Zawsze coś się prześlizgnie. Wiedzą o tym firmy takie jak Google, czy Facebook, które pomimo utrzymywania jednych z najlepszych specjalistów od bezpieczeństwa ogłaszają programy typu Bug Bounty, co pozwala tanim kosztem pozyskać dodatkowe informacje o dziurach w oprogramowaniu.
NSA dysponuje olbrzymim budżetem (oficjalnym i tzw. “czarnym”). Część z tego budżetu wydawałbym na kupno exploitów z “rynku”. Są specjalistyczne firmy, które szukają błędów i sprzedają je później agencjom rządowym (np. VUPEN, który na pewno sprzedawał swoje 0day’e do NSA). Istnieją także tzw. brokerzy, którzy skupują 0day’e od “młodych, zdolnych” i sprzedają je później “wyżej”.
I tu dochodzimy do punktu kulminacyjnego mojego felietonu:
- NSA znalazło Heartbleeda samo, lub nie znalazło i kupiło od brokera 0day’ów — nie ma to znaczenia, w każdym z tych scenariuszy mogło swobodnie i niepostrzeżenie wykorzystywać ten błąd do kradzieży danych z serwerów inwigilowanych osób. Możnaby zażartować, że jeśli zespół wykwalifikowanych mózgów z NSA, którego jedynym zadaniem jest szukanie błędów w kodzie źródłowym “na pełnym etacie” nie był wstanie odnaleźć tego buffer underrunu w kodzie OpenSSL samodzielnie, to możemy spać spokojnie — nic nam nie grozi. Błąd! Dlaczego? Ponieważ to czy:
- NSA wiedziało lub nie wiedziało o Heartbleedzie — nie ma znaczenia, w swoim arsenale mają szereg innych exploitów/0day’ów, o czym często wspominał Edward Snowden.
Jak widać, niezależnie od umiejętności analityków NSA, i tak, jako obywatele innego niż USA kraju, mamy przechlapane. Brak “wewnętrznych” umiejętności NSA rekompensuje posiadany przez agencję ogromny budżet i rynek handlu exploitami 0day.
Skoro ja na to wpadłem…
Zaproponowana przeze mnie strategia działania NSA nie powinna być zaskoczeniem dla nikogo, kto ma cokolwiek wspólnego z branżą bezpieczeństwa lub służbami dedykowanymi elektronicznemu wywiadowi. Jestem pewien, że w NSA pracują bardziej doświadczeni, a na pewno “podlejsi” ode mnie ludzie ;) …skoro więc ja na to wpadłem, to zapewne NSA realizuje tę politykę już od lat. Jest też bardziej niż pewne, że robi o wiele więcej.
I wy też robilibyście to samo na ich miejscu, gdybyście mieli w ten sposób ustawione cele i taki budżet oraz wpływy…
NSA oczywiście zaprzecza
NSA oficjalnie zaprzeczyło, jakoby wiedziało o błędzie Heartbleed wcześniej:
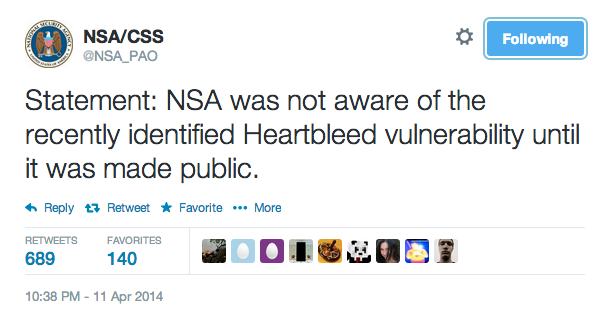
NSA zaprzecza, że wiedziało o Heartbleed
Zarówno w oświadczeniu NSA jak i samego Baracka Obamy przeczytać można:
Rządowe serwery USA także korzystają z OpenSSL do ochrony prywatności urzędników i obywateli. Gdybyśmy wcześniej wiedzieli o tej podatności, ujawnilibyśmy ją w odpowiedzialny sposób developerom OpenSSL”
Postawię więc kilka pytań bez odpowiedzi:
Czy, gdybyście wiedzieli o błędzie takiej klasy, trzymalibyście go dla siebie narażając na atak infrastrukturę rządową własnego kraju? Przecież skoro “my” wiemy, to może wiedzą także “oni” (Chińczycy, Rosjanie…)?
Nie jest łatwo wykraść klucz prywatny atakiem Heartbleed
Cloudflare wykonało mały eksperyment, który po części sugeruje, że być może od kilku dni zupełnie niepotrzebnie emocjonujemy się Heartbleedem, bo nie jest on znowuż tak użytecznym dla służb atakiem…
Cloudflare wystawiło serwer z podatną na atak wersją biblioteki OpenSSL i poprosiło wykradzenie jego klucza prywatnego. Klucz udało się pozyskać 2 internautom, pierwszy wykonał 2,5 miliona zapytań, drugi pozyskał klucz w “tylko” 100 000 żądań. W trakcie ataków zrestartowano jednak serwer i podejrzewa się, że to mogło pomóc w umieszczeniu w pamięci klucza prywatnego tuż po restarcie.
Epilog
Biorąc pod uwagę wyniki eksperymentu Cloudflare’a, czy NSA miałoby trzaskać miliony zapytań, żeby zyskać klucz prywatny do serwera? A jednocześnie w niedawnych sprawach sądowych, udawać że klucza nie mają i wnioskować o niego? Przypomnijmy, że właśnie o klucz prywatny do certyfikatu SSL NSA prosiła właściciela serwisu Lavabit, na którym skrzynkę miał Edward Snowden. Dlaczego nie skorzystali z Heartbleedu do wycągnięcia klucza? A może jednak skorzystali i zrobili teatrzyk?
Obawiam się, że NSA ma szereg innych asów w rękawie, dzięki którym może, w sprzyjających okolicznościach, pozyskiwać nie tylko klucze prywatne do certyfikatów SSL. W końcu połączenia szyfrowane najłatwiej podsłuchiwać przez kompromitację końcówki kryptograficznej …a te pracują pod kontrolą nie tylko jednej, dziurawej biblioteki SSL, ale szeregu innego rodzaju oprogramowania …i sprzętu.
Jeśli to was nie przekonuje do zmiany haseł do wszystkich serwerów, do których logowaliście się na przestrzeni ostatnich 2 lat, to pewnie jesteście ludźmi, którzy nie mają nic do ukrycia ;)
Dziwne połączenia na port 443 z 2013 roku
EFF donosi, że już w 2013 jeden z administratorów zauważył próbę połączenia na 443, przedwcześnie zerwaną, ale wykonującą połączenie heartbeatowe.
Zdarzenie to dało się namierzyć, ponieważ administrator ten miał włączone “bogate” logowanie ruchu. Pytanie, czy ktoś jeszcze zaobserwował takie próby połączeń? Pochodziły one z adresacji 193.104.110.12 oraz 193.104.110.20, należącej do botnetu, który stara się nagrywać ruch w sieciach IRC… (czy to brzmi jak agencja wywiadowcza?).
Na koniec, zgodnie z obietnicą, piosenka — na lepszą pogodę ducha, żeby lżej wam było na …sercu ;)
Serwery ciekną w rytmie heart-bit
Pamięć zrzucają w rytmie heart-bit
Ujawniaj miły swe tokeny
I swoje hasła też pokazuj mi (…i NSA, cza cza cza)
PS. Mam też dla Was 2 inne artykuły: :s/NSA/Chiny/ga oraz :s/NSA/Rosja/ga


 Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów!
Weź udział z kolegami w jednym z naszych 8 cyberwykładów. Wiedzę podajemy z humorem i w przystępny dla każdego pracownika sposób. Zdalnie lub u Ciebie w firmie. Kliknij tu i zobacz opisy wykładów! Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Każdy powinien zobaczyć te krótkie szkolenia! Niektóre z nich są darmowe. Wszystkie to praktyczna wiedza i zrozumiały język. 6 topowych tematów — kliknij tutaj i zobacz szczegółowe opisy.
Ta piosenka ma zostać hymnem niebezpieczinka :D
Na serwerach rządowych mógł nawet być włączony heartbeat, i nawet mógł wyglądać na podatny na atak, jednak dane “ujawniane” za jego pomocą mogły być specjalnie ustawione.
Warto chyba jednak dodać, że wciąż kluczowym źródłem informacji i wpływów dla wszystkich agencji są źródła OSOBOWE i INSTYTUCJONALNE. Technologiczne mogą je wspomagać, ale ostatecznie to, czy ktoś konkretny po prostu puści parę lub udostępni uprawnienia, zależy jedynie od siły użytego nacisku. Jak nie ten osobnik lub firma, to inny.
Dlatego nie ma co panikować, że agencje mogą zdobyć informacje, bo i tak mogą. Pytanie właściwe brzmi: czy chcą/potrzebują.
Wiecie co oznacza FBI? Federalna Banda Idiotów. A wiecie co oznacza NSA? Narodowi Schizofrenicy Ameryki.
To było takie suche, że nie wiem sam jak to opisać.
świetny artykuł Piotrze. +1
Jedno co mnie zastanawia: czy nagłośnienie informacji o błędzie nie było celową zagrywką aby “wymusić” aktualizację openssl do wersji która posiada inny, możliwy do wykorzystania błąd. Brzmi jak teoria spiskowa, ale spora część krytycznych błędów nie jest nagłaśniana, tylko dyskretnie usuwana/naprawiana a w tym przypadku jest inaczej.
Tez sie nad tym zastanawialem…
Paranoicy tego swiata laczmy sie ;)
Pozdrawiam.
Andrzej
Druga teoria spiskowa ktora urodzila sie w mojej glowie jest nastepujaca… Halas zwiazany z heartbleedem to tzw. “smoke screen”… Ciekawe co przepychaja nam za plecami podczas gdy wiekszosc oczu patrzy na ta glosna dziure w openssl… znow jakas cispa, acta czy inne pieronstwo…
Pozdrawiam.
Andrzej
Na co ktoś miałby robić aferę z aktualizacją, skoro ludzie i tak aktualizują? Nie dzisiaj to za tydzień-dwa pójdzie razem z aktualizacją z repo i nikt nie zwróci uwagi. A tak to teraz wszyscy gapią się na OpenSSL. Zresztą sam możesz sprawdzić, co jest w aktualizacji. Commit do wersji ‘g’ jest tak mały, że ktoś musiałby być geniuszem, żeby ukryć w niej błąd poważniejszy niż Heartbleed.
O dziurach rzadko w mediach “ogólnych” pojawia się informacja z kilku powodów. Większość dziur jest mało sensacyjna, zainteresowanie tematem jest małe, dziennikarze nawet o nich nie wiedzą, producenci zamkniętych rozwiązań robią wszystko w celu ukrycia informacji itepe itede. Tutaj jest wrzask, bo “internet się zepsuł”. I w sumie to będzie jedyny przekaz, jaki zrozumie większość społeczeństwa.
Kolejną ACTA jest oczywiście TTIP. Ale na ukrywanie bugiem OpenSSL to trochę za późno, nawet gdyby założyć prawdziwość takich działań ;).
Szczerze mówiąc, to podejrzewam, że po błędach w iOS i GNU/TLS ludzie zaczęli macać inne biblioteki i tyle.
Emocje związane z NSA są zrozumiałe w USA. W ich przypadku instytucje państwowe wystąpiły przeciwko obywatelom i wartościom, którym miały służyć. Zatem lamenty za oceanem są oczywistą reakcją na kolejne takie doniesienia. Europa i inne kraje też powinny wyrazić dezaprobatę dla tych działań, ale już tylko z powodów politycznych – z moralnego punktu widzenia nie możemy nic agencjom amerykańskim¹ zarzucić, bo przecież taka jest ich rola i w interesie USA leży zdobywanie informacji o innych. Nasi robią to samo i naiwnością byłoby mieszać moralność w politykę międzynarodową.
Argument, że serwery amerykańskie również były podatne jest chybiony. Zakłada bowiem, że NSA kieruje się rozsądkiem. Wątpię, by ktokolwiek tutaj wierzył, że tak jest. Dla wyimaginowanej ochrony bezpieczeństwa zapewne “jest to poświęcenie, na które są gotowi”².
Czy niełatwo wykraść klucz to trudno powiedzieć. Cloudflare wystawiło 2 serwery, do których wykonano 2.6M zapytań z 2 sukcesami (1.3M/sukces). Liczby wydają się duże, ale zapomnieliście o trzech sprawach:
1. 1.3M potrzeba do wyciągnięcia klucza, a nie do wyciągnięcia jakichkolwiek sensownych danych.
2. Co w przypadku, gdy zamiast wysyłać dużo zapytań do jednego serwera, wysyła się mało zapytań do wielu serwerów? Do masowego zbierania danych jest to też dużo lepsza strategia. 1.3M serwerów przeskanowanych na godzinę i w ciągu roku jest z 9 tysięcy³ kluczyków, a nikt się nie połapie.
3. Lokalizacje uzyskiwane przez testujących były zapewne przypadkowe. Haczyk w tym, że Heartbleed ma drugie dno. OpenSSL nie używa `calloc` do alokacji, tylko własnej puli pamięci kontrolowanej przez kolejkę. De Raadt już swoją tyradę na temat świadomego ominięcia zabezpieczeń przed takimi atakami wygłosił, ale jest jeszcze jedna sprawa: przy [stosunkowo] niewielkiej puli i prostych zależnościach między otrzymywanymi blokami możnaby się pokusić o takie dobranie czasu wykonywania zapytań, żeby uzyskane lokalizacje nie były tak bardzo przypadkowe.
Ciekawe uzupełnienie: http://www.tedunangst.com/flak/post/heartbleed-vs-mallocconf
Podsumowując: rok 2014 zapamiętamy jako czas, kiedy w krótkim czasie 3 różne implementacje SSL poległy z powodu… pseudooptymalizacji.
____
¹ Liczba mnoga, bo przecież to nie tylko NSA nas szpieguje ;).
² Lord Farquaad – “Shrek”, USA 2001
³ Zakładam, że kilkadziesiąt MB/s to dla NSA nie problem; pomijam też powtarzające się klucze, bo 9k to nadal mała liczba w porównaniu do liczby wszystkich kluczy.
“z moralnego punktu widzenia nie możemy nic agencjom” – padlem. Tresura glupich robi swoje. Niedlugo dla takich jak mpan moralne bedzie przerabianie na mydlo wlasnych obywateli, bo przeciez sa to obywatele panstwa X, wiec panstwo X moze robic nimi chce. Ej, kurcze, ale to juz bylo!
Niektórym przydałaby się tresura z czytania ze zrozumieniem.
“Dodajmy, że nawet jeśli projekt nie ma dostępnego kodu źródłowego, to błędy bezpieczeństwa też można z łatwością w nim znajdować” a znalazłeś jakiś że tak piszesz ?:)
Być może co do ogółu znajdowania błędów poprzez reverse engineering Piotrek z tym “z łatwością” przesadził, ale w kontekście podanego przez niego przykładu fuzzingu Adobe przez gyna i j00ru to jednak “z łatwością” rzeczywiście pasuje jak ulał, co z resztą widać po rezultatach :].
@rik
“w kontekście podanego przez niego przykładu fuzzingu Adobe przez gyna i j00ru to jednak “z łatwością” rzeczywiście pasuje jak ulał”
Nie każdy bug jest podatnością i nie każda podatnośc stanowi problem. Gdyby znajdowanie błędów bezpieczeństwa znajdujących praktyczne (wrogie) zastosowanie było takie proste, to zamiast płacić bug bounty firmy wynajmowałby 100 hinduskich programistów czy też wspomnianych amerykańskich studentów żeby w łatwy i oczywisty sposób wszystkie błedy znaleźc i wyeliminować. Murowany sukces – EULA bez dziwnych ograniczeń, rzetelna reklama 100% error free itd. Niestety do kodu wolnego od błędów wciąż jest daleko, a dopóki rynek nie wymusi odpowiadzialności producentów oprogramowania za błędy, to wszyscy będziemy beta testerami produktów.
Po ostatnich wydarzeniach takich jak Target czy OpenSSL rośnie świadomość decydentów w firmach, za chwilę zaczną się od wszystkiego ubezpieczać, a po wypłacie pierwszych odszkodowań firmy ubezpieczeniowe zaczną wywierać presję na doskonalenie kodu, infrastruktury i poprawki w EULA – pytanie tylko kiedy to nastąpi.
Widzę ruch w interesie, klienci którzy przez X lat nie interesowali się swoimi IPSami teraz zaczęli czytać raporty, statystyki, zestawienia i zadawać pytania. Mam nadzieję, że ten trend się utrzyma.
@lubas
Nawet nie chce myslec ile beda kosztowaly aplikacje/systemy itp. jak producent bedzie musial “brac za nie odpowiedzialnosc”. Nie ma, nie bylo i nie bedzie programu bez bledow i podatnosci. To se ne da. Wiec z automatu kazdy producent bedzie musial byc ubezpieczony. A jezeli ryzyko jest tak duze, to firmy zapewne chetnie beda ubezpieczac, tylko ze za odpowiednio wysokie skladki.
@Tomek K – jak kupujesz jogurt, telewizor, samochód, dom – to oczekujesz, a nawet masz ustawowo zagwarantowaną odpowiedzialność sprzedawcy/importera/dystrybutora. Jeżeli telewizor eksploduje i wyrządzi szkody, to opowiedzialność za szkody nie jest ograniczona do jego wartości. Proste i intuicyjne. Dlatego telewizory nie wybuchają.
Twórcy oprogramowania nie ponoszą odpowiedzialności na tych samych zasadach, dlatego programy wybuchają :)
Czy byłoby drogo? Firmy deweloperskie na pewno miałyby szansę na zniżki w stawkach ubezpieczniowych, pod warunkiem poświęcenia X zasobów na badanie, testowanie, ulepszanie produktu. To jak z ubezpieczeniem zdrowotnym, jesli się często serwisujesz, dobrze prowadzisz, nie masz nadwagi i nałogów to nie jest źle. Palący, pijący, otłuszczony miłośnik hedonizmu zapłaci sporo.
To że jest jak jest, nie oznacza że tak musi być.
@lubas:
Większej i równie niebezpiecznej bzdury już dawno nie słyszałem. Zamiast mądrzyć się na temat odpowiedzialności, napisz w życiu chociaż jeden poważny program. Wtedy pogadamy. Łatwo jest teoretyzować, nie mając pojęcia o temacie.
Przeciętny program pisany przez studenta pierwszego roku informatyki jest bardziej złożony niż jakikolwiek sprzęt, jaki masz u siebie w mieszkaniu. Mało w historii powstało konstrukcji, które złożonością osiągają zabawki, które na projekty zaliczeniowe pisze student ostatniego roku. O prawdziwym sofcie nie wspominając.
Gdybyś chciał wymagać dowodzenia poprawności działania programów, to w tej chwili nie pisałbyś tego posta, tylko srał z radości na widok kalkulatora, który potrafi dodać dwie 5-cyfrowe liczby. To nie jest układ elektroniczny, gdzie masz ze 20 typowych bazowych układów sprawdzonych i przebadanych przez ostatnie 30 lat, a twoim zadaniem jest kilka z nich połączyć i sprawdzić krótką checklistę albo wręcz skopiować gotowca od innego producenta, zmieniając tylko 2-3 rzeczy, żeby ominąć prawo patentowe. Analogicznie jest w każdej innej dziedzinie i tak właśnie powstaje każdy sprzęt, który masz w domu.
Natomiast oprogramowania w ten sposób nie zrobisz. Każdy poważniejszy program to terra incognita, którą dopiero odkrywamy. Istnieje szereg zasad sztuki, które zmniejszają szansę powstania problemów. Istnieją narzędzia ułatwiające ich wykrycie. Ale nikt nie będzie konstruował dowodu na prawidłowość działania programu. Po pierwsze ze względu na trudność: dla czegokolwiek większego niż bubelsort to już nie są sprawy trywialne. Po drugie ze względu na potrzebne zasoby: dowiedzenie poprawności działania niejednego nawet prostego programu wymagałoby tyle czasu i pieniędzy, że nigdy nie ukazałby się na rynku – jeśli w ogóle udałoby się to zrobić do końca istnienia wszechświata. Po trzecie dlatego, że bardzo często nie znamy sposobu na skonstruowanie takiego dowodu, a metoda ogólna nie istnieje (co zostało dowiedzione). Jeżeli uważasz inaczej, to proszę bardzo: udowodnij, że poniższy program się zakończy dla __każdego__ n początkowego większego od 0:
Dopóki n ≠ 1: jeżeli n jest parzyste: n = n / 2, w przeciwnym przypadku: n = 3 · n + 1.
Good luck.
A twoja propozycja, oprócz oczywistej bzdurności, jest dodatkowo niebezpieczna. Rzecz pierwsza: jeżeli sądzisz, że to producenci zapłacą za błędy, to się grubo mylisz. Producenci nie produkują pieniędzy, więc nie mają z czego zapłacić. Zapłacą wszyscy konsumenci, a w ostatecznym rozrachunku – osoby pracujące. Czyli domagasz się, żebyś TY SAM (i każdy inny) musiał ponosić odpowiedzialność za błędy producentów.
Rzecz druga: gratuluję pomysłu na jeszcze większą centralizację i skupienie jeszcze większej kontroli nad rynkiem w rękach jeszcze węższej grupy. Bo w momencie, gdy trzeba będze ponosić takie koszty, to na rynku zostanie jedynie kółko wzajemnej adoracji niewielkiej liczby dużych firm. Żaden niezależny developer nie będzie mógł pracować, bo ryzyko będzie zbyt wielkie. Chyba że proponujesz obowiązkowe ubezpieczenie. Tak, wtedy zostaną… oczywiście wraz z kompensacją ryzyka spowodowaną istnieniem ubezpieczenia, kosztami ubezpieczenia ponoszonymi przez ciebie (kolejny raz nie przez producentów) i uśmiechem na gębach ubezpieczycieli.
@mpan
ad: złożoność programów
Większośc sprzętów które mam w domu, to konstrukcje mechaniczne, elektroniczne lub elektroniczne, które zawierają również programy (firmware). Złożoność takiej konstrukcji jest większa niż samego programu – CBDU. Poza tym nie róbmy jaj, prosty parser czy kompilator na zaliczenie nijak mają się do projektu wielowarstwowego PCB operującego z częstotliwością x GHz.
ad: projekty zaliczeniowe
Zgaduję, że jesteś na etapie fascynacji swoja profesją, marzysz o $10k na miesiąc i deprecjonujesz pracę innych. Moim zdaniem o wiele więcej niepewności niesie praca nad siłami przyrody (np. konstruowanie silników spalinowych, samolotów) – gdzie nie zawsze teoria zgadza się z praktyką, niż praca z dobrze udokumentowanym, przewidywalnym kompilatorem. Niemniej za dobrą robotę darzę szacunkiem tak samo konstruktora mechanika, lekarza i programistę.
ad: sranie, oczywista bzdurnośc itd – pominę milczeniem
ad: przerzucenie kosztów na konsumenta. Rynek to skoryguje i znajdzie punkt równowagi. Istnienie branży wyłączonej z normalnych reguł postępowania nie jest normalne. W teh chwili nie płacisz za ubezpieczenie producenta oprogramowania, ale Twój bank/szpital/dostawca prądu z powodu potencjalnych błędów w oprogramowaniu za które nikt nie zapłaci musi… kupować ubezpieczenia oraz wprowadzać nadmiarowość i systemy bezpieczeństwa które też kosztują i są przerzucane na konsumenta. Płacisz zawsze, kwestia czy będziesz płacił za produkt solidny czy za wieczną wersję beta.
@lubas
ad firmware:
Firmware sprzętu, który masz w domu, nie spowoduje szkód. Chyba że sąsiad ze wściekłości wyrzuci telewizor przez okno i spadnie ci na głowę ;). Szkody, za które producenta mógłbyś skutecznie pozwać, może spowodować tylko część analogowa. Bardzo rzadko kiedy oprogramowanie w µc może na nią wpłynąć tak, by coś się stało. Zatem niczego nie udowodniłeś, bo to oprogramowanie w sprzęcie nadal nie ma żadnych gwarancji. To samo dotyczy układów pracujących na gigahercowych częstotliwościach – one szkód nie zrobią, więc liczy się tylko zapewnienie, że działają. Masz rację, że ich projektowanie jest skomplikowanym procesem. Ale ja nie mówiłem o złożoności w kontekście tworzenia, tylko w kontekście testowania, bo tego dotyczy twój pomysł. A testowanie jest robione z automatu przez oprogramowanie, które przeprowadza szereg testów – po raz kolejny trywialnych w porównaniu do tego, z czym mamy do czynienia przy tworzeniu softu.
ad deprecjonowanie pracy innych:
Nie bardzo wiem, gdzie deprecjonuję pracę innych. Prace zaliczeniowe na studiach są zabawkami w porównaniu do poważnego oprogramowania. Zaprzeczysz? I w żaden sposób nie ujmuje to nic studentom. A, ponad wszystko, nie opisywanie pracy studentów było celem tego akapitu, tylko porównanie złożoności.
ad praca nad siłami przyrody:
Masz rację, przy silnikach, samolotach etc. często teoria nie zgadza się z praktyką. W przypadku programów nie ma niezgodności teorii z praktyką… bo nie ma teorii.
Niewiele też daje fakt, że kompilator jest dobrze udokumentowany (żaden nie jest). gcc ma w tej chwili ok. 2500 możliwych opcji i konia z rzędem temu, kto zna chociaż 50 z tych najczęściej używanych na jego platformie. Ba.. ręka królewny temu, kto mi z pamięci poda, jaki wpływ na wynik kompilacji ma -O3 i w jakich sytuacjach UB spowoduje zawsze wygenerowanie błędnego kodu. Ale kompilator niewiele ma do rzeczy, bo mowa jest o poprawności działania kodu, a na to kompilator wielkiego wpływu nie ma. Sytuacje, że program “psuje się” z powodu buga w kompilatorze są skrajnie rzadkie. Prawie zawsze przyczyną jest to błąd autora kodu.
ad rynek:
Rynek skoryguje i znajdzie punkt równowagi – masz rację. Tym punktem będzie właśnie przerzucenie kosztów na konsumentów. I masz też rację, że teraz już płacimy za błędy. Jednak będziemy za nie płacili i tak, bo one były, są i zawsze będą. Koszty z nimi związane nie znikną dlatego, że producent będzie musiał wypłacać odszkodowania.
To, co można wprowadzić, to karanie (autentyczne karanie przez wymiar sprawiedliwości, nie odszkodowania w procesach cywilnych) za karygodne naruszenie zasad sztuki, celowe wprowadzanie błędów, świadome ich ukrywanie etc. Tylko niestety nie jest już tak prosto skonstruować konkretne przepisy do tego. O wiele prostszym byłoby po wprostu wprowadzić kapitalizm, ale na to nie ma zbyt wielu chętnych.
ad wyłączenie branży:
“Normalnych reguł” czyli jakich? Sugerujesz, że istnieją jakieś uniwersalne reguły dotyczące wszystkich branż? Nigdy o takich nie słyszałem. Na każdą branżę nakładane są określone wymagania, ale są one zupełnie od siebie nie zależne i nałożenie ich na jedną nie oznacza, że “dla równości i sprawiedliwości” nakłada się je na inne. Na producenta jogurtu (czy żywności w ogóle) nakładane są jedne wymagania, na producentów elektroniki inne, na producentów samochodów inne, na producentów części do samolotów jeszcze inne. A na inne nie są nakładane w ogóle – koniec, kropka. Zresztą tak się składa, że kilka norm dla branży software w Polsce powstało. Są olewane przez wszystkich – producentów, konsumentów i urzędników. Na szczęście, bo nawet twój post nie mógłby powstać – jest niezgodny z normą określającą, że jedynym dopuszczalnym kodowaniem w Polsce jest iso-8859-2…
@lubas: “przewidywalny kompilator”, HA HA HA HA… dawno się tak nie uśmiałem.
Chyba Ty jesteś “na etapie fascynacji swoją profesją”. Zdarzało mi się już wykrywać błędy w kompilatorach oraz wykłócać się z developerami tychże, że błąd naprawdę jest. Musiałem robić triki w kodzie, żeby ominąć bugi w kompilatorze – albo wręcz kawałki w asemblerze pisać. I co z tego, że może byłbym w stanie udowodnić poprawność tej konkretnej pętli “for” – skoro kompilator mi tę poprawność rozwalał, wstawiając złą instrukcję skoku warunkowego? (przy włączonej “optymalizacji” – a bez niej kod puchł * 10 i nie mieścił się w pamięci). Ba, raz nawet głupie mnożenie 32-bitowe (z 64-bitowym wynikiem) było do dupy – musiałem napisać w asemblerze (dwie instrukcje, hehe). To tyle o “przewidywalności” kompilatorów. A co tu gadać o “aplikacjach” typu Łoffis.
A teraz dowiedzial sie ktos niepowolany i tez zaczal korzystac. Wiec luka “wyszla na jaw” przez jedna z najbardziej umoczonych w inwigilacje organizaczji czyli Google. Szczerze, gdybym dzis mieszkal w USA i mial wystarczajaco duzo pieniedzy uciekalbym z tego kraju, wraz z rodzina, gdzie pieprz rosnie. Ten kraj niedlugo stanie sie autentyczna trescia 1984. Pisze w 100% serio.
Najwyraźniej jednak nie mieszkasz w USA i nie masz dużo pieniędzy, więc nie musisz uciekać. Mieszkasz w Europie, więc możesz sobie spokojnie walczyć z ciemiężcą opanowującym cały świat wprost ze swojego cieplutkiego fotela, robiąc z wroga sito błękitnymi ptaszkami…
Na szczęście mieszkas w Polsce i nie musisz się tym martwić ;)
Pozdrawiam
@Radom Tak, NA SZCZESCIE mieszkam w Polsce. I to takze pisze w 100% powaznie.
Mieszkasz w Polsce, z radością oddajesz 50-80% swoich zarobków za puste obietnice, uwielbiasz jak urzędnicy r****ą cię w d**** i święcie wierzysz, że cię te wredne USA uchronią przed złym niedźwiedziem, jak ten posmakuje w słodkim kremie i sięgnie łapką dalej…
Zarejestrujcie firmę na Słowacji, to wtedy nie będziecie oddawać tyle kasy na te bezduszne żmije.
“Co ja robiłbym na miejscu NSA?” – TO świetnie ze autor dzieli się z nami swoimi przemyśleniami i oświeca nas czym jest wywiad tylko jaki to ma związek z tym o czym pisał Bloomberg ? Bardzo miły i ciekawy tekst ale raczej nie artykuł tylko felieton bądź też opowiadanie.
Jak to jaki. Już w tytule masz powiązanie tematu tego wpisu z artykułem Bloomberga. Ten felieton [nawet Piotrek go nazywa felietonem w którymś z akapitów] moim zdaniem pięknie pokazuje, że nie pierwszy Heartbleed i nie ostatni. I że pewne serwisy [tu: Bloomberg] piszą o NSA, bo chyba jak artykuł ma NSA to się nieźle klika. Bo czy to rzeczywiście materiał na artykuł, że NSA miała lub nie miała informacje na temat tego błędu wcześniej? Moim zdaniem Bloomberg ugryzł temat od dziwnej strony, niezrozumiałej zupełnie. Pytanie, dlaczego?
Wciąż jeszcze da się (jakoś) żyć – komputer można wyłączyć, gotówki można używać, algorytmy rozpoznawania twarzy w tłumie wciąż szwankują, drony dopiero są nieśmiało wdrażane, do odczytywania aktywności mózgu wciąż potrzeba masy elektrod umieszczanych przy głowie, rozpoznawanie siatkówki oka z dystansu w fazie badań, pełnego kodu genetycznego indywidualnych osób wciąż jeszcze się w bazach danych nie składuje. Za to przy obecnym rozwoju technologii życie za jakieś 100 lat zapowiada się ciekawie :D
(@TrashO2) Jeśli nie zrobi tego “nasza” agencja, to zrobi to inna, obca, która nie będzie miała skrupułów do wykorzystania tych informacji. Również do przerabiania wrogich społeczeństw na “mydło”.
Jeszcze musisz trochę dorosnąć do wniosku, że władza nad światem to wzajemne obrzucanie sie gównem i żadne święte oburzenie tego nie zmieni.
@nocman (???) Ekhm, jak juz nauczysz sie wypowiadac spokojnie i rzeczowo, bez histeri czy innych emocji, napisz ponownie o co Ci chodzilo, a wtedy ewentualnie sie do tego odniose, OK?
“Czy, gdybyście wiedzieli o błędzie takiej klasy, trzymalibyście go dla siebie narażając na atak infrastrukturę rządową własnego kraju? Przecież skoro “my” wiemy, to może wiedzą także “oni” (Chińczycy, Rosjanie…)?”
Jako “agencja”? Tak trzymalbym go dla siebie… Kazalbym moim minionom napisac patcha do heartbeat i zaktualizowal sobie openssl na “moich” serwerach i na kluczowych serwerach rzadowych (jesli nie w sposob bezposredni to wykorzystujac heartbleed mozna sie przeciez wbic na taki serwerek i dodac pare zmian ;)) a potem po cichu uzywal tej dziury do podsluchu / zbierania danych od innych. Jak sprawdzic czy Rosjanie i Chinczycy wiedza o bledzie? To proste… Zrobic im nieautoryzowany audyt bezpieczenstwa. Przeciez atak przy pomocy tej dziury jest nie do wykrycia… ;)… Gdyby okazalo sie ze inne agencje / inne kraje tez sie zapatchowaly po cichu wycieklbym dane o heartbleedzie do publiki po to by uniemozliwic im uzycie tej dziury :)… Mozliwosci heartbleed daje sporo… Przejmujesz dane osoby na wysokim szczeblu (login i haslo e-mail) i nie tylko mozesz podsluchiwac ale np. wyslac obrazliwego maila do “kamrata” i spowodowac rozlam… NSA jest jak “Pinki i mozg” oni co noc proboja przejac wladze nad swiatem… MUAHAHA…
Jako osoba prywatna zglosilbym taki blad prawie natychmiast ;). Najpierw bym chwile sie pobawil :P… zaspokoil ciekawosc :P…
Pozdrawiam.
Andrzej
A ja sobie tak myśle, po co szukać dziur w programach, jak można zrobić w kompilatorze fają furtkę. Do każdego programu kompilator dodawałby kilka linijek dzięki którym najbezpieczniejszy kod dostawałby tylne drzwi. Jest takie coś możliwe ?
@Piotrze
Wydaje mi się, że istnieje pewna osoba dysponująca danymi dzięki którym można by udowodnić czy NSA rozpoznała błąd w Heartbeat w ciagu ostatnich 2 lat.
Tą osobą jest J Alex Halderman – twóra ZMAPa, który na konferencji 30c3 opowiadał o swoim narzędziu (zmap skanuje cały zakres IPv4 w czasie poniżej godziny). W trakcie testowania tego narzędzia wykonywał on testy skanujące między innymi port 443. Innymi testami, ktore przeprowadzal było zbieranie publicznych kluczy. Fakt – nie daje nam to bezpośredniej informacji o heartbeacie, ani o tym czy NSA załatało swoje serwery lub serwery o znaczeniu krytycznym, jednak jeśli jego testy wykonane byly przynajmniej kilka razy w trakcie tych 2 lat, to znajdujac w morzu danych adresy należące do NSA i sprawdzajac czy w ciagu ostatnich 2 lat nastapiła “fala aktualizacji” certyfikatów lub innych parametrow odkrytych przy skanowaniu – dałoby nam to obraz pewnej anomalii – zachowania niecodziennego, które dawało by sygnał, że jednak o czymś wiedzieli.
Może nic byśmy nie znaleźli ale wydaje mi się, że gra jest warta świeczki.
Problem: USA i ich prawo eksportowe powoduje, że Alex oficjalnie prawdopodobnie nigdy takich danych nie udostępni społeczeństwu IT/SEC, chyba, że takiej analizy zaczną domagać się międzynarodowe wpływowe media/korporacje.
Otóż to, nawet jeśli ktoś ma “materiał dowodowy”, jest jeszcze szereg innych czynników (polityczno-prawnych), które mogą pogrzebać te rewelacje na wieki. Może uda się przekonać twórcę Shodana, aby zapisywał szereg parametrów z negocjacji połączeń (a nie tylko same nagłówki)?
@dadoks:
Jasne że jest to możliwe. Gdzieś czytałem że już w latach 80′ ktoś wysnuł teorię o złośliwym kompilatorze, jednak by coś takieg uskutecznić, trzebaby przejść przez mur społeczności. Bo co innego błąd w logice programu, gdzie żądanie większej ilości danych niż zadeklarowano powoduje odesłanie danych spoza zadeklarowanego zakresu (wyciek pamięci), a co innego jawnie napisana funkcja add_backdoor() ;)
Mówię tu oczywiście o open source, bo do CS mogą Ci dodać co chcą, dlatego tak ważne z punktu widzenia bezpieczeństwa jest korzystanie z OS narzędzi i, jeśli to newralgiczne biblioteki/ programy-demony działające z roota, szczodre sypanie grajcarami na audyty kodu.
BTW sam jestem zwolennikiem teorii spiskowych i w żadne zapewnienia Wielkiego Brata że o niczym nie wiedział nie wierzę. Teatrzyk trzeba odegrać dla mas.
Wlasnie po twoim poscie przyszlo mi cos do glowy.
NSA oficjalnie ujawnilo ze dostarczylo fragmenty kodu dla Androida i IOS. W przypadku Androida gdzie kod Open source jest publiczny i dość popularny, backdoor musiałby być napisany w sposób zakamuflowany i dzialac podobnie do bledu Heartbleed.
Proszę zauwazyc, ze ten blad jest pozornie niewidoczny na pierwszy drugi i trzeci rzut oka i polega na tym ze określone fragmenty normalnego kodu, oddzialuja w pewien ukryty jednak określony sposób z kompilatorem. Heartbleed to nie jest blad kodu, to jest blad tego ze kompilator w pewien sposób traktuje określone fragmenty tego kodu. Można to naprawić albo poprzez zmiane kodu albo poprzez zmiane kompilatora, ponieważ procesor wykonuje kod assemblera, nie zas C++, Java itp…
Jeśli wiec NSA wpuscila do Androida kawałki kodu, to wydaje mi się dość prawdopodobne ze one dzialaja wlasnie w sposób podobny do heartbleed tzn. określone specyficzne działanie powoduje nieoczekiwana reakcje skompilowanego przez jakiś kompilator kodu C++
Te problemy by nie wystepowaly gdyby kluczowe fragmenty kodu były napisane w Assemblerze…
@dadoks
Coś takiego nie jest możliwe. Przede wszystkim dlatego, że kompilator nie rozumie semantyki programu, a jest to warunek konieczny dla jej zmiany w ukierunkowany na konkretne działanie sposób. Kompilator jest niczym więcej niż translatorem pomiędzy jednym językiem a drugim. “Rozumie” pojedyncze zdania, ale nie zrozumie fabuły powieści. Ty natomiast pytasz właśnie o zmianę fabuły w ściśle określony i zaplanowany sposób. Nawet gdyby kompilator był w stanie zrozumieć sens przetwarzanego kodu, co zapewne nastąpi wraz z postępem technologicznym, to kod odpowiedzialny za “rozumienie” byłby na tyle duży, złożony i zasobożerny, że trudno byłoby go ukryć w źródłach.
Możliwe jest oczywiście wstrzyknięcie niechcianego kodu. Ale to już raczej zadanie dla linkera, nie kompilatora. I efekt będzie zupełnie różny od tego, czego oczekujesz. Po prostu będzie dodatkowy kod odpalany i tyle. W latach 90-tych był wirus, który infekował narzędzia w pakiecie – jeśli mnie pamięć nie myli – Borlanda. Potem budowane nimi programy były zainfekowane. Ale to była sztuka dla sztuki z dzisiejszego punktu widzenia.
Możliwe jest też wykonanie bardziej złożonego ataku, gdzie złośliwie zmodyfikowany kompilator wyprodukuje kod wpływający na działanie konkretnej biblioteki. Przykładowo celowo może – udając optymalizację – wyprodukować dla fragmentu biblioteki kryptograficznej kod posiadający nieoczekiwane właściwości dotyczące czasu wykonania lub wpływu na cache. Takie podatności w sprzyjających okolicznościach mogą pozwolić atakującemu np. wykraść klucz. Jednak to jest już taka teoretyczna zabawa na granicy science-fiction, a zastosowanie miałoby tylko do ataków wymierzonych w ściśle wybrane cele. Czyli trudny do wykonania, niepewny i drogi atak o niewielkim polu rażenia. Obstawiam, że gumowa pałka będzie tańsza. Nawet gdyby do kosztów doliczyć zniknięcie pracownika ambasady (co nie jest tanie, bo nad zniknięciem takiego obiektu nikt nie przejdzie obojętnie) ;).
@lisu
Widzę, że fascynaci teorii spiskowych doczekali się zjawiska analogicznego do pro-ana. Nie wiem, czy jest sens dyskutować, ale osób, które mogłyby się złapać na takie argumentowanie i powiększyć armię mięsa do trzepania na nich kasy, kilka słów wyjaśnienia:
> Jasne że jest to możliwe.
Zaprezentuj więc, w jaki sposób jest możliwe.
> Gdzieś czytałem że już w latach 80′ ktoś wysnuł teorię o złośliwym kompilatorze
Gdzieś czytałem, że już w latach -2k pne ktoś wysnuł teorię o płaskiej Ziemi podtrzymywanej przez żółwie. O dziwo Ziemia płaska nie jest, a wskazany przez ciebie pomysł prof. dr. /rehab./ Ktosia nie doczekał się realizacji nawet przez samego autora.
> by coś takieg uskutecznić, trzebaby przejść przez mur społeczności.
Nie, wystarczy usiąść przy klawiaturze i napisać.
> Bo co innego błąd w logice programu, gdzie żądanie większej ilości danych niż zadeklarowano powoduje odesłanie danych spoza zadeklarowanego zakresu (wyciek pamięci)
Wyciek pamięci to coś “trochę” innego. Ale użycie profesjonalnie brzmiącej nazwy daje +10 do autorytetu…
> a co innego jawnie napisana funkcja add_backdoor()
W dwóch poprzednich błędach z SSL z tego roku (iOS, GNU/TLS) tak właśnie było. I, paradoksalnie, to właśnie te add_backdoor()-owate przypadki wyglądały na celowy atak bardziej niż Heartbleed.
> Mówię tu oczywiście o open source, bo do CS mogą Ci dodać co chcą, (…)
Przyjmując początkowe założenie – o skutecznym ataku ze strony kompilatora – różnica pomiędzy zamkniętym a otwartym źródłem jest żadna. Atak następuje już po weryfikacji kodu.
@assembler
Poprzednik przynajmniej zachował pozory tego, że wie, o czym pisze. Może nawet pofatygował się, żeby podstawy wiedzy zdobyć, bo skądś “wyciek pamięci” znał. A tutaj komedia od początku do końca.
>Proszę zauwazyc, ze ten blad jest pozornie niewidoczny na pierwszy drugi i trzeci rzut oka i polega na tym ze określone fragmenty normalnego kodu, oddzialuja w pewien ukryty jednak określony sposób z kompilatorem.
Nic nie oddziaływuje w żaden sposób z kompilatorem. Kompilator służy do przekształcenia czytelnego dla człowieka kodu źródłowego na czytelny dla procesora kod maszynowy (ew bytecode lub inny podobny format). Jest to jednorazowa operacja wykonywana na komputerze developera lub buildserverze i na tym związki programu z kompilatorem się kończą. Błąd w całkowicie jawny sposób używał fragmentu tablicy, którego nie powinienbył używać. Używał, bo autor potraktował niezaufane dane jako zaufane i nie sprawdził zakresu. Błąd, jaki każdy programista popełniał w życiu wiele razy. Tylko tutaj z jednej strony z szeregu powodów pozostał niezauważony, a z drugiej znalazł się w szczególnie niewłaściwym miejscu.
> Heartbleed to nie jest blad kodu, to jest blad tego ze kompilator w pewien sposób traktuje określone fragmenty tego kodu.
Owszem, to jest tylko i wyłącznie błąd kodu. Wystarczy sprawdzić commita z poprawką. Kompilator w żaden szczególny sposób nie traktuje tego fragmentu kodu i działanie kompilatora nie miało nic wspólnego z wystąpieniem błędu. Kompilator potraktował ten kod dokładnie tak, jak wymaga tego od niego specyfikacja języka. Jest napisane “wyślij dane od B do B + L” i kompilator wygenerował kod, który wysyła dane od B do B + L. Problem w tym, że kod powinienbył sprawdzić, czy L nie jest zbyt duże. Kod tego nie robił.
> Można to naprawić albo poprzez zmiane kodu albo poprzez zmiane kompilatora, ponieważ procesor wykonuje kod assemblera, nie zas C++, Java itp… (…)
Wiele “mądrych” słów i nazw, ale zdanie nie ma nawet sensu. “Bezbarwne zielone idee wściekle śpią”. btw: procesor nie wykonuje kodu asemblera, tylko kod maszynowy. Kod asemblerowy musi zostać przetworzony na kod maszynowy przez asemblera, żeby procesor mógł go wykonać.
> Te problemy by nie wystepowaly gdyby kluczowe fragmenty kodu były napisane w Assemblerze…
Te problemy nie występowałyby, gdyby zostało napisane w języku asemblerowym – to prawda. Głównie dlatego, że albo OpenSSL nigdy nie zostałby napisany, albo miałby tyle krytycznych błędów, że poległby zanim ktokolwiek miałby szansę usłyszeć o Hertbleed. I tylko dlatego. Błąd jest w braku wykonania operacji, która również musiałaby zostać wykonana, gdyby program został napisany w języku asemblerowym. Nawet gdyby ktoś napisał to bezpośrednio w kodzie maszynowym, to musiałaby zostać napisana. Nie została i tyle.
@mpan
http://cm.bell-labs.com/who/ken/trust.html
Kompilator nie rozumie semantyki ale może wykrywać pewne sekwencje kodu i reagować na nie.
@zdegustowany
Przytoczony artykuł prezentuje to, o czym pisałem w ostatniej części odpowiedzi do dadoksa: złożony atak wymierzony w konkretne oprogramowanie. Tylko w dużo prostszym wydaniu niż to, co możnaby zastosować w praktyce. I wykonany w bardzo sprzyjających warunkach. Zresztą sam autor zauważył trafnie: “Such blatant code would not go undetected for long”.
Autor równie dobrze zauważa: “I could have picked on any program-handling program such as an assembler, a loader, or even hardware microcode”. Możliwo�??ć przeprowadzenia jakiegokolwiek ataku poprzez modyfikację narzędzi/środowiska nie jest czymś, co możnaby podważyć. Autor to pokazał na praktycznym przykładzie, który dzisiaj już chyba nikogo nie zdziwi (w latach 80-tych to mogła być jakaś nowość). Ale takie zmodyfikowanie kompilatora lub innego elementu, by zmienił znaczenie kodu na podstawie sensu jego działania, nie było wymierzone w konkretny kod, działało w praktyce i jeszcze nie było to widoczne gołym okiem w commitach kompilatora, to na razie fantastyka.
Jeszcze w temacie ‘czy nsa wiedziało i czy ichniorządowe serwery były podatne’: tego się nigdy nie dowiemy, ale bardzo prawdopodobne że tak. Chociażby po to, by wychwytywć kto z błędu korzysta (przecież odpowiednią regułką iptables można ten błąd zablokować nawet na podatnych wersjach openssl, więc można skonstruować regułkę tak, by przepuszczać te cieknące keep-alive’y i logować adres i czas połączenia). Poświęcenie swoich obywateli? A bo to pierwszy raz? xD Jedna z teorii spiskowych głosi że 9/11 było szeroko zakrojoną akcją rządową mającą na celu przeforsować konieczność wzmocnienia ochorny antyterrorystycznej w oczach opinii publicznej. Śmierć tysiąca obywateli? “poświęcenie, na jakie jesteśmy gotowi”, bo to jest ‘ekonomicznie uzasadnione’ :)
Moim zdaniem jest szansa, na sprawdzenie czy NSA wiedziało – patrz mój komentarz powyżej – #comment-302895
Noo, widzę że j00ru się ładnie wybił, co do Gyna to była kwestia czasu ;) Pamiętam ich jeszcze z UW-Forum (pzdr Unki ;>).
Powołali się na dwie osoby ? Czyżby Snovden się sklonował…
Piotrek, być może pisząc o zespole studentów poszukujących luk w oprogramowaniu Open Source miałeś na myśli kurs D. J. Bernsteina, który właśnie tego dotyczył (amerykański profesor – pasuje :-)
http://cr.yp.to/2004-494.html
Długo szukałem artykułu na /., który mam gdzieś na końcu języka. Niestety nie pamiętam ani nazwiska, ani tego, w jakich projektach znaleźli błędy (jednym był chyba Open Office). Sprawa sprzed mniej wiecej 10 lat. Może i ten Bernstein pasuje…
@mpan
Piszac cytuje “Poprzednik przynajmniej zachował pozory tego, że wie, o czym pisze. Może nawet pofatygował się, żeby podstawy wiedzy zdobyć, bo skądś “wyciek pamięci” znał. A tutaj komedia od początku do końca.” pokazujesz wszystkim jak latwo sprowadzić dyskusje do poziomu rynsztoka poprzez BRAK SZACUNKU DLA ADWERSARZA.
[b]Chcialbym widzieć ze autor tej strony będzie reagowal w sposób odpowiedni na tego rodzaju brak kultury jeśli chce utrzymać profesjonalny poziom strony.[/b]
A do rzeczy merytorycznych Piszac
“Wiele “mądrych” słów i nazw, ale zdanie nie ma nawet sensu. “Bezbarwne zielone idee wściekle śpią”. btw: procesor nie wykonuje kodu asemblera, tylko kod maszynowy. Kod asemblerowy musi zostać przetworzony na kod maszynowy przez asemblera, żeby procesor mógł go wykonać.” pokazujesz tylko, ze nie rozumiesz ze Asembler to kod maszynowy, a nie rozumiejąc tego czym jest nie znajdujesz sensu mojej wypowiedzi. Potwierdzasz to wręcz pisząc dalej:
“Jest napisane “wyślij dane od B do B + L” i kompilator wygenerował kod, który wysyła dane od B do B + L. Problem w tym, że kod powinienbył sprawdzić, czy L nie jest zbyt duże. Kod tego nie robił.”
Assembler tym się roznil od dajmy na to C++ ze aby napisac na nim cos musisz wiedzieć ile dokładnie jest to B czy L, to wlasnie w jezykach wyższego rzedu musisz sprawdzać czy cos nie jest za duże za male lub inaczej sformułowane.
Generalnie próbujesz pokazac ile to wiesz, ale tak naprawdę tylko pokazales jak mało wiesz… Moja teza wynikla wlasnie z konkluzji analizy bledu zawartej na tej stronie:
http://blog.existentialize.com/diagnosis-of-the-openssl-heartbleed-bug.html
“Given how difficult it is to write safe C, I don’t see any other options”
> Piszac cytuje “(…)” pokazujesz wszystkim jak latwo
> sprowadzić dyskusje do poziomu rynsztoka poprzez
> BRAK SZACUNKU DLA ADWERSARZA.
Grubo się mylisz, ale jednocześnie masz rację. Masz rację, że okazałem brak szacunku. Sam go siebie pozbawiłeś, pisząc poprzedniego posta. Mylisz się w tym, że zostałeś potraktowany przeze mnie jako przeciwnik w dyskusji. Nie prowadzę bowiem dyskusji z tobą – to byłoby pozbawione sensu. Wyjaśniam innym osobom, które będą twoje wywody czytały, w czym rzecz. Te komentarze czyta wiele osób, które nie mają zbyt wiele wspólnego z informatyką lub dopiero się uczą. Mogą bardzo łatwo paść ofiarą takich pseudonaukowych tworów. Np. Dadoks wydaje się początkującym i zadał sensowne pytanie, ale niechcący mógłby uwierzyć w to, co tutaj wymyślacie z lisu.
Wyjaśniając kolejną radosną twórczość:
> Assembler tym się roznil od dajmy na to C++
> ze aby napisac na nim cos musisz wiedzieć ile
> dokładnie jest to B czy L, to wlasnie w jezykach
> wyższego rzedu musisz sprawdzać czy cos nie jest
> za duże za male lub inaczej sformułowane.
Języki wyższego poziomu sprawdzają to same. Im niżej, tym więcej trzeba sprawdzać ręcznie. Np. w Javie ten problem w ogóle nie mógłby wystąpić, bo język nie daje konstrukcji, która pozwalałaby odwołać się poza faktycznie istniejący obiekt, na którym obecnie operujemy. W najtoszym przypadku poleci wyjątek. Języki asemblerowe, odwzorowujące prawie 1:1 kod maszynowy, nie dają żadnej weryfikacji, czy użyte przesunięcie mieści się w określonym zakresie. C przynajmniej “zna” pojęcie zmiennych, więc kompilator jest w stanie – i np. gcc to robi – dać tu i ówdzie ostrzeżenia np. o dostępnie do nizainicjalizowanych danych albo dziwnych odwołaniach. Ponieważ C opisuje jako-tako strukturę programu, to zewnętrzne narzędzia są też w stanie wykryć jeszcze więcej błędów. Są nawet w stanie wykryć wyjście poza zaalokowaną pamięć, ale tutaj to nie mogło zadziałać, bo autorzy OpenSSL zrobili własną alokację z puli, o czym valgrind nie mógłby wiedzieć. W przypadku języków asemblerowych jest jedna gigantyczna przestrzeń adresowa i tylko logika programu określa strukturę poszczególnych jej fragmentów. Asembler lub zewnętrzne narzędzia na podstawie kodu nic nie wywnioskują, a kod nie wskazuje nawet na możliwość powstania problemu, bo nie widać wcale, jaka jest struktura danych w pamięci.
> Generalnie próbujesz pokazac ile to wiesz,
Jedyne, co próbuję pokazać, to uwidocznić, że ktoś tutaj wymyśla teorie nijak mające się nie tylko do rzeczywistości, ale nie mające nawet żadnej wartości merytorycznej.
> ale tak naprawdę tylko pokazales jak mało wiesz…
To już niech ocenią czytający na podstawie zapoznania się z tematem. Wątpię, by kogokolwiek interesował poziom mojej wiedzy, bo nie o mnie tutaj chodzi.
> Moja teza wynikla wlasnie z konkluzji analizy bledu zawartej na tej stronie:
Żeby wyciągać konkluzje na temat rzeczy złożonych, trzeba najpierw zrozumieć podstawy.
> http://blog.existentialize.com/diagnosis-of-the-openssl-heartbleed-bug.html
> “Given how difficult it is to write safe C, I don’t see any other options”
Piękne wyrwanie cytatu z kontekstu dla podparcia własnej tezy całkowicie odwrotnej od tej prezentowanej przez autora oryginalnego tekstu. Zachęcam wszystkich do przeczytania zacytowanego artykułu.
którzy na tapet wzięli popularną open ….
tapetĘ.
Pozdrawiam
A właśnie, że nie ;)
@niebezpiecznik:
Dlaczego dopuszczasz ewidentny brak kultury w dyskusji???
@mpan
Ciesze się ze przyznales dwie rzeczy:
1. Brak w twojej wypowiedz podstawowej kultury na forum. Brak szacunku dla oponentow to taki papierek lakmusowy skad się wyszlo…
2. To ze przyznales w końcu ze asembler to kod maszynowy, mimo ze wcześniej napisales cos dokładnie innego.
Ewidentnie NIE CHCESZ zrozumieć o co mi chodzi. Wiec tak krotko, bo brzydzę się schodzeniem do twojego poziomu dyskusji.
Piszac kod w jezykach wyższego poziomu, nigdy nie masz pewności jaki kod wygeneruje kompilator. Changelogi kompilatorow sa pelne bug fixow, polegających na tym, żeby dobrze napisany kod, był poprawnie kompilowany, a tzw. cross platformowe aplikacje zawierają wręcz wstawki napisane bezpośrednio pod konkretne kompilatory.
Ty nie czujesz jak działa assembler stad i nie wiesz ze:
1. Języki asemblerowe, odwzorowujące prawie 1:1 kod maszynowy, nie dają żadnej weryfikacji, czy użyte przesunięcie mieści się w określonym zakresie, ponieważ to PROGRAMISTA MUSI TO ZWERYFIKOWAC. Nie robi tego za niego cos innego, ale to on sam musi o tym pomyslec.
2. W przypadku języków asemblerowych jest jedna przestrzeń adresowa. Jej wielkość określa system operacyjny i to PROGRAMISTA KONTROLUJE JAK JA ZAPELNIC, wlaczajac to jaka jest struktura danych w pamięci.
Napisanie dobrego programu w Assemblerze jest trudne, jest czasochłonne i wymaga ZROZUMIENIA jak działa procesor, ale dzięki temu, ze w pełni kontrolujemy co komputer robi, nie sprawia niespodzianek. Jedyna niespodzianka jaka nas może czekac, to lekcja pokory wynikajaca z tego, ze jednak czegos nie wiedzieliśmy…
> Piszac kod w jezykach wyższego poziomu, nigdy
> nie masz pewności jaki kod wygeneruje kompilator.
Każdy kompilator generuje kod o działaniu, które musi być identyczne z kodem źródłowym. Zatem każdy ma pewność, co kompilator wygeneruje. W tym przypadku wygeneruje kod pobierający dane spod wskazanego miejsca w pamięci. Kod był przewidywalny i całkowicie zgodny z oczekiwaniami. W bugu Hartbleed kompilator wygenerował dokładnie to, co programista napisał. Programista jedynie przekazał niewłaściwe dane do fragmentu kodu. Mógłby je przekazać w dowolnym innym języku – także w językach asemblerowych. Skutki byłyby:
– W języku asemblerowym: takie same, jak tego buga.
– W C, zakładając brak poolingu pamięci: w najgorszym przypadku takie same, ale nie przeszłyby testów valgrindem. W praktyce na wielu platformach nie miałyby dużo mniejsze znaczenie. Np. na OpenBSD `free` może czyścić pamięć; na wszystkich platformach domyślną funkcją alokacyjną powinno być `calloc`, który zawsze czyści pamięć i gwarantuje brak przepełnień przy wyliczaniu rozmiaru tablicy jednowymiarowej; itd.
– W C++ przy wykorzystaniu właściwych kontenerów (np. vector): nie ma możliwości powstania w/w błędu bez naprawdę głupiej pomyłki albo świadomego zepsucia czegoś przez programistę.
– W językach wyższego poziomu: nie ma możliwości powstania w/w błędu bez świadomego zepsucia czegoś przez programistę, bo nie istnieją konstrukcje, które pozwoliłyby się odwołać poza właściwe obszary.
Języki asemblerowe, będąc bliskimi 1:1 odwzorowaniami kodu maszynowego, z założenia muszą umożliwiać wykonanie wszystkich błędów z jęzków wyższego poziomu. W przeciwnym przypadku nie byłyby one możliwe w tychże językach.
> Changelogi kompilatorow sa pelne bug fixow,
> polegających na tym, żeby dobrze napisany kod, był poprawnie kompilowany,
Bugów, które rzadko wpływają na cokolwiek w praktyce. Właśnie dlatego bugreporty do oprogramowania rzadko okazują się spowodowane przez błędy kompilatora.
> a tzw. cross platformowe aplikacje zawierają wręcz wstawki napisane
> bezpośrednio pod konkretne kompilatory.
Zawierają wstawki napisane pod konkretne implementacje bibliotek, używanych przez aplikację. Biblioteki nie mają nic wspólnego z kompilatorem.
> Ty nie czujesz jak działa assembler stad i nie wiesz ze:
(Dlatego jako prawdę podano cytat mojej własnej wypowiedzi…)
> 1. Języki asemblerowe, odwzorowujące prawie 1:1 kod maszynowy, nie dają żadnej
> weryfikacji, czy użyte przesunięcie mieści się w określonym zakresie,
> ponieważ to PROGRAMISTA MUSI TO ZWERYFIKOWAC.
> Nie robi tego za niego cos innego, ale to on sam musi o tym pomyslec.
W C jest dokładnie tak samo i właśnie z tego wyniknął błąd Heartbleed. Programista nie zweryfikował, do czego się odwołuje. W języku asemblerowym zrobiłby ten sam błąd.
> 2. W przypadku języków asemblerowych jest jedna przestrzeń adresowa.
> Jej wielkość określa system operacyjny
Rozmiar przestrzeni adresowej jest określony przez platformę sprzętową, nie system. System operacyjny decyduje jedynie, które obszary tej przestrzeni adresowej zmapować na faktyczną pamięć operacyjną.
> i to PROGRAMISTA KONTROLUJE
> JAK JA ZAPELNIC, wlaczajac to jaka jest struktura danych w pamięci.
Niewątpliwie decyduje. Tak samo zresztą jak w C oraz wielu innych językach kompilowanych bezpośrednio do natywnego kodu. Nie bardzo widzę, co z tego miało wyniknąć.
> Napisanie dobrego programu w Assemblerze jest trudne,
> jest czasochłonne i wymaga ZROZUMIENIA jak działa
> procesor, ale dzięki temu, ze w pełni kontrolujemy
> co komputer robi, nie sprawia niespodzianek.
Napisanie dobrego programu w kodzie asemblerowym jest dla człowieka niewykonalne, jeżeli ma to być jakikolwiek bardziej złożony program. Właśnie dlatego opisuje się programy w językach wyższego poziomu, a kompilatorowi zleca się wygenerowanie dla nich kodu maszynowego.
> Jedyna niespodzianka jaka nas może czekac, to lekcja pokory
> wynikajaca z tego, ze jednak czegos nie wiedzieliśmy…
Albo wyjście poza zakres tablicy… czyli to, co zrobił autor Heartbleeda.
@assembler:
> Napisanie dobrego programu w Assemblerze jest trudne,
> jest czasochłonne i wymaga ZROZUMIENIA jak działa
> procesor, ale dzięki temu, ze w pełni kontrolujemy
> co komputer robi, nie sprawia niespodzianek.
Ani w pełni nie trzeba rozumieć procesora (jeśli wydaje ci się, że rozumiesz to tylko dlatego, żę tak naprawdę nawet nie wiesz jak procesor działa), ani też w pełni nie kontrolujesz co komputer robi. (sobie googlnij branch prediction, speculative execution albo memory paging).
@mpan: “Napisanie dobrego programu w kodzie asemblerowym jest dla człowieka niewykonalne”
Oczywiście, że jest. Nawet obiektowo w asemblerze można pisać :-P oczywiście jest to dużo trudniejsze i bardziej pracochłonne, więc po co się męczyć, jeśli nie ma bezwzględnej potrzeby. Niemniej programiści-masochiści się zdarzają, na wszelkich poziomach abstrakcji. Znałem jednego, co w czasach wczesnego Qt w gołym Xlibie pisał… można, tylko po co…
@c: “Ani w pełni nie trzeba rozumieć procesora (jeśli wydaje ci się, że rozumiesz to tylko dlatego, żę tak naprawdę nawet nie wiesz jak procesor działa), ani też w pełni nie kontrolujesz co komputer robi. (sobie googlnij branch prediction, speculative execution albo memory paging).”
Do napisania zwykłego programu bynajmniej nie trzeba “w pełni rozumieć procesora”, zwłaszcza, jeśli ma on działać na wielu różnych procesorach,a tym bardziej, jeśli ma działać na maszynie wirtualnej (JVM na ten przykład)… ani nie trzeba “pełnej kontroli”, od tego jest system operacyjny i okolice. Jak już ktoś pisze system operacyjny, to też nie w każdej jego części trzeba…
Optymalizację pod przewidywanie skoków, przetwarzanie potokowe, zmianę kolejności wykonywania instrukcji, wielokrotne ALU i inne wynalazki lepiej zrobi kompilator niż człowiek. To znaczy, człowiek (nie jeden), dobrze znający procesor, zrobił to raz, ogólnie, kodując optymalizator, i więcej nie trzeba. Mózg by ci wyparował, jakbyś przy każdym skoku zastanawiał się, jaką instrukcję skoku wstawić, lub jaką flagę do niej, albo jak poprzestawiać instrukcje przed nią i za nią…
Stronicowanie w normalnych systemach z podziałem czasu też nie nie zależy od programisty “użytkowego”, tylko od systemu operacyjnego i okoliczności – co się jeszcze wykonuje, co inni użytkownicy robią, jak ułożyły się czasowo dane z wejść i tak dalej i tak dalej…
“Pełną kontrolę” to możesz mieć nad 51ką, Atmelkiem czy innym maluchem. Coś takiego w przypadku współczesnych “potworów” wielordzeniowych nie ma sensu, po to buduje się warstwy abstrakcji, żeby nie babrać się w nieskończoność w szczegółach. Ogólna implementacja wykorzystująca możliwości sprzętu wystarczy, choć niby “dałoby się lepiej” na “gołym metalu” – ale koszt napisania tego w ten sposób, i utrzymywania tego w stanie “ręcznie zoptymalizowanym” byłby astronomiczny – wersji procków w samej rodzinie Intela jest około mnóstwo, nowe podwersje wchodzą co pół roku czy rok, a co dopiero mówić o wersjach takiego programu na inne maszyny? toż to napisanie od zera tego samego.
Jak już potrzeba wycisnąć ze sprzętu ostatnie soki (jakiś brute force cracking czy shitcoin mining), to się FPGA zaprzęga, a zaraz potem ASICa robi, a nie ręcznie optymalizuje asembler. Jak ktoś chce względnie tanio, to na GPU…
a który przepis kodeksu karnego karze zabrania informować o rozmowach ze służbami?
Dygresja:
Jeżeli świat potrafił załatać dziurę w OpenSSL w przeciągu kilkunastu godzin od wykrycia Heartbleeda, to to samo mogła zrobić agencja NSA 2 lata temu na swoich serwerach (ile tam posiadają miliardów budżetu?). Co więcej, najbardziej zastanawiające jest to, że ten “feature” “pojawił się” w oprogramowaniu. Nie jest wynikiem źle napisanego kodu, przeoczeń programistów, on się nagle stał, ktoś go zaimplementował. Podstawowym pytaniem jest fakt, czy implementacji nie dopuściło się samo NSA bądź inna agencja rządowa, a jak dobrze wiemy również z innych publikowanych tu artykułów, NSA na amerykańskich firmach wymusza stwarzanie backdoorów, a projekty takie jak TrueCrypt oficjalnie przyznały, że były do tego namawiane. Skupmy się na prawdopodobieństwie.
“A jednocześnie w niedawnych sprawach sądowych, udawać że klucza nie mają i wnioskować o niego?” – tak, szanownego Pana, tak to wlasnie dziala. Proponuje sie obudzic.
jeżeli NSA wiedziała, to znaczy że sama ten bug wstawiła, bo każdy inny przez kogoś odkryty bug się szybko rozchodzi a nie przez 2 lata jest w tajemnicy
Ciekawe ile dziur ma “niebezpiecznikowy wordpress”?…
Widze na dole strony działający exploit “echo date”.
rtykuł odbiega niekorzystnie od poprzednich 3 na ten temat.Dzięki E. Snowdenowi pewnie prawie wszyscy wiedzą co to jest NSA i jak bardzo zła to agencja.
Drobny problem, który w tej sensacji jakby umykał nawet większości piszących na tym forum, a więc jednak dość wąskiej grupie zainteresowanych problematyką, polega na tym, że NSA z pewnością nie jest jedyną firmą, która mogła być zainteresowana luką w OpenSSL i w cale nie wiadomo, czy jest nie jest ona najgorszą z tego grona (co niektórzy tutaj zauważyli).
Nie chodzi mi o wybielanie NSA – po sensacjach Snowdena pewnie wszyscy od razu taki wariant wzięli pod uwagę. Tylko, ze faktów (pomijając oczywiste, jak NSA i ten bug) w zasadzie brak, jest tylko narzucająca się samoczynnie plotka, że NSA mogła znać ten błąd.
Zresztą jest to nawet prawdopodobne. Tyle, że chodzi tu o błąd w kodzie dostępnym dla każdego i pewnie każdy zainteresowany (z różnych powodów) go badał i mógł odkryć. Nawet bez przeprowadzenia stosownych badań można założyć, że wiele (o ile nie wszystkie) podobnych do NSA instytucji, których nie brakuje, zajmuje się badaniem możliwości w zakresie wykorzystania luk w oprogramowaniu odpowiedzialnym za funkcjonowanie Sieci, z którego spora część jest dostępna ze źródłami, i w innych popularnych i przez to użytecznych aplikacjach.
Jak kilka osób na tym forum skłonny byłbym jednak uznać NSA za niekoniecznie najbardziej zagrażającą mojej egzystencji. Błąd był w kodzie dostępnym dla każdego i każdy zainteresowany mógł to go odkryć.Z kolei tajemnicze przypadki “kompromitowania” wirtualnych serwisów, których całkiem sporo było w ostatnim roku, a za które obwiniano (pewnie w części słusznie) przeglądarkowe panele administracyjne tychże serwerów i administratorów, dowodzić mogą, że ostatnio ten błąd znany był nie tylko NSA (o ile w ogóle był znany tej agencji).
Z opisu błędu wynika zresztą, że mógł być po prostu dziełem przypadku i niestaranności. Tyle, ze zdarzyło się to w kodzie odpowiedzialnym za podstawowe usługi kryptograficzne internetu. Zwolennicy teorii spsikowych nigdy w przypadki nie wierzą, tym niemniej prosta obserwacja świata wskazuje, że zdarzają się właśnie głownie niespodziewane przypadki.
Moim zdaniem, gdyby tylko NSA go odkryła, to można by spać w miarę spokojnie. NSA to Zło, oczywiście. Ale spośród innych Złych, lokuje się raczej po naszej stronie.
Czego nie można powiedzieć raczej o agencji z którą zapewne ma do czynienia obecnie niejaki Snowden, kandydat do pokojowego nobla nb.
Ogólnie rzecz biorąc używanie jednego sposobu kodowania samo w sobie jest porażką.
0dayów, bez debiloapostrofu. to nie skrót ani nazwisko z niemą samogłoską
Proponuję również “Serduszko Puka” w wersji Wet Fingers:
:s/NSA/Chiny/ga Do czego to sluzy jak tego uzyc z gory dzieki.